Удалить последнюю строку из файла в bash
у меня есть файл, foo.txt , содержащий следующие строки:
Я хочу простую команду, которая приводит к содержимому foo.txt время:
11 ответов
на не существует GNU sed версии 3.95, так что вы должны использовать его в качестве фильтра с временным файл:
конечно, в этом случае вы также можете использовать head -n -1 вместо sed .
Это, безусловно, самое быстрое и простое решение, особенно для больших файлов:
Если вы хотите удалить верхнюю строку, используйте это:
что означает выходные линии, начинающиеся с линии 2.
не используйте sed для удаления строк из верхней или нижней части файла-это очень медленно, если файл большой.
у меня были проблемы со всеми ответами здесь, потому что я работал с огромным файлом (
300Gb), и ни одно из решений не масштабировалось. Вот мое решение:
in words: узнайте длину файла, который вы хотите получить (длина файла минус длина его последней строки, используя bc ) и установите эту позицию в конец файла (по dd ing один байт /dev/null на него).
это быстро, потому что tail начинает читать с конца, и dd перезапишется файлом на месте вместо того, чтобы копировать (и анализировать) каждую строку файла, что делают другие решения.
Примечание: это удаляет строку из файла на месте! Сделайте резервную копию или тест на фиктивный файл, прежде чем попробовать его на свой собственный файл!
удалить последнюю строку из файла без чтения всего файла или переписывания чего-либо, вы можете использовать
чтобы удалить последнюю строку, а также распечатать ее на stdout («pop»), вы можете объединить эту команду с tee :
эти команды могут эффективно обрабатывать очень большие файлы. Это похоже на ответ Йоси и вдохновлено им, но позволяет избежать использования нескольких дополнительных функций.
если вы собираетесь использовать эти повторно и хотите обработку ошибок и некоторые другие функции, вы можете использовать
Если вы хотите удалить только последнюю строку без изменения самого файла, сделайте
Если вы хотите удалить последнюю строку сам входной файл делаем
sed -i » -e ‘$ d’ foo.txt
Для Пользователей Mac :
на Mac, head-n -1 не будет работать. И я пытался найти простое решение [ не беспокоясь о времени обработки], чтобы решить эту проблему только с помощью команд» голова «и/или» хвост».
я попробовал следующую последовательность команд и был рад, что могу решить ее, просто используя команду «хвост» [с параметрами, доступными на Mac ]. Итак, если вы находитесь на Mac и хотите использовать только «хвост» для решения этой проблемы, вы можете использовать эту команду :
файл cat.txt / tail-r / tail-n +2 / tail-r
объяснение :
1 > tail-r: просто меняет порядок строк на своем входе
2 > tail-n +2: это печатает все строки, начиная со второй строки на входе
Как использовать sed для удаления последних n строк файла
Я хочу удалить некоторые n строк из конца файла. Можно ли это сделать с помощью sed?
например, чтобы удалить строки от 2 до 4, я могу использовать
но я не знаю номера строк. Я могу удалить последнюю строку, используя
но я хочу знать, как удалить n строки с конца. Пожалуйста, дайте мне знать, как это сделать, используя sed или какой-либо другой метод.
20 ответов
Я не знаю sed , но это можно сделать с помощью head :
Кажется, то, что вы ищете.
забавный и простой sed и tac устранение :
Примечание
- двойные кавычки » необходимы для оболочки для оценки $n переменная
Если hardcoding n является опцией, вы можете использовать последовательные вызовы sed. Например, чтобы удалить последние три строки, удалите последнюю строку трижды:
использовать sed , но пусть оболочка делает математику, с целью использования d команда, давая диапазон (чтобы удалить последние 23 строки):
удалить последние 3 строки, изнутри:
дает количество строк файла: say 2196
мы хотим удалить последние 23 строки, поэтому для левой стороны или диапазона:
выдает: 2174 Таким образом, оригинальный sed после оболочки толкование:
С -i делать inplace edit, файл теперь 2173 строки!
можно использовать глава для этого.
$ head —lines=-N file > new_file
где N-количество строк, которые вы хотите удалить из файла.
содержимое исходного файла минус последние N строк теперь находятся в new_file
просто для полноты, я хотел бы добавить мое решение. Я закончил тем, что сделал это со стандартным ed :
этого удалить последние 2 строки, используя редактирование на месте (хотя это тут использовать временный файл в /tmp !!)
Это может сработать для вас (GNU sed):
для усечения очень больших файлов действительно на месте у нас есть . Он не знает о линиях, но tail + wc можно конвертировать строки в байты:
существует очевидное условие гонки, если файл записывается одновременно. В этом случае может быть лучше использовать head — он подсчитывает байты с начала файла (mind disk IO), поэтому мы всегда будем усекать на границе строки (возможно, больше строк, чем ожидалось, если файл активно записывается):
удобный один-лайнер, если вы не войти попытка поставить пароль вместо имени пользователя:
с ответами здесь вы бы уже узнали, что sed не лучший инструмент для этого приложения.
однако я думаю, что есть способ сделать это с помощью sed; идея состоит в том, чтобы добавить N строк, чтобы удерживать пространство, пока вы не сможете читать, не нажимая EOF. При попадании в EOF распечатайте содержимое hold space и завершите работу.
команда sed выше опустит последние 5 строк.
большинство приведенных выше ответов, похоже, требуют команд/расширений GNU:
Удаление строк из файла с использованием sed
В Unix команда SED удаляет одну или несколько строк из указанного файла по желанию пользователя. Эта утилита используется для работы с командной строкой Unix, для удаления из файла выражений, которые могут быть идентифицированы с помощью определяющего разделителя (например, запятая, табуляция или пробел), по номеру строки или путем поиска строки, выражения или адреса строки в синтаксисе sed.

Sed: удалить одну или несколько строк из файла
Синтаксис
string = ряд символов, найденный в строке
regex = регулярное выражение, соответствующее искомому шаблону
addr = адрес строки (номер или шаблон)
Примеры Sed
Вот несколько примеров использования приведенного выше синтаксиса.
Используйте следующий код, чтобы удалить третью строку:
Удалите строку, содержащую ряд букв «awk», используя:
Вы можете удалить последнюю строку, введя:
Или удалить все пустые строки:
Удалить строку, соответствующую регулярным выражениям (путем исключения одного из них, содержащего цифровые символы, как минимум 1 цифру, расположенные в конце строки):
Удалить интервал между строками 7 и 9:
Та же операция, что и приведенная выше, но с заменой адреса параметрами:
Вышеприведенные примеры отображают изменения только при открытии файла (stdout1 = screen).
Для постоянных изменений в старых версиях (ниже 4) используйте временный файл для GNU sed с использованием команды -i [suffix]:
Изображение: © John Schnobrich — Unsplash.com
Несколько слов благодарности всегда очень кстати.
Команда sed Linux
Команда sed — это потоковый редактор текста, работающий по принципу замены. Его можно использовать для поиска, вставки, замены и удаления фрагментов в файле. С помощью этой утилиты вы можете редактировать файлы не открывая их. Будет намного быстрее если вы напишите что и на что надо заменить, чем вы будете открывать редактор vi, искать нужную строку и вручную всё заменять.
В этой статье мы рассмотрим основы использования команды sed linux, её синтаксис, а также синтаксис регулярных выражений, который используется непосредственно для поиска и замены в файлах.
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая
шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
число
— начиная от строки номер и до строки номер которой будет кратный числу.Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \ — любой символ в количестве i;
- \ — любой символ в количестве от i до j;
- \ — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
Примеры использования sed
Теперь рассмотрим примеры sed Linux, чтобы у вас сложилась целостная картина об этой утилите. Давайте сначала выведем из файла стройки с пятой по десятую. Для этого воспользуемся командой -p. Мы используем опцию -n чтобы не выводить содержимое буфера шаблона на каждой итерации, а выводим только то, что нам надо. Если команда одна, то опцию -e можно опустить и писать без неё:
sed -n ‘5,10p’ /etc/group
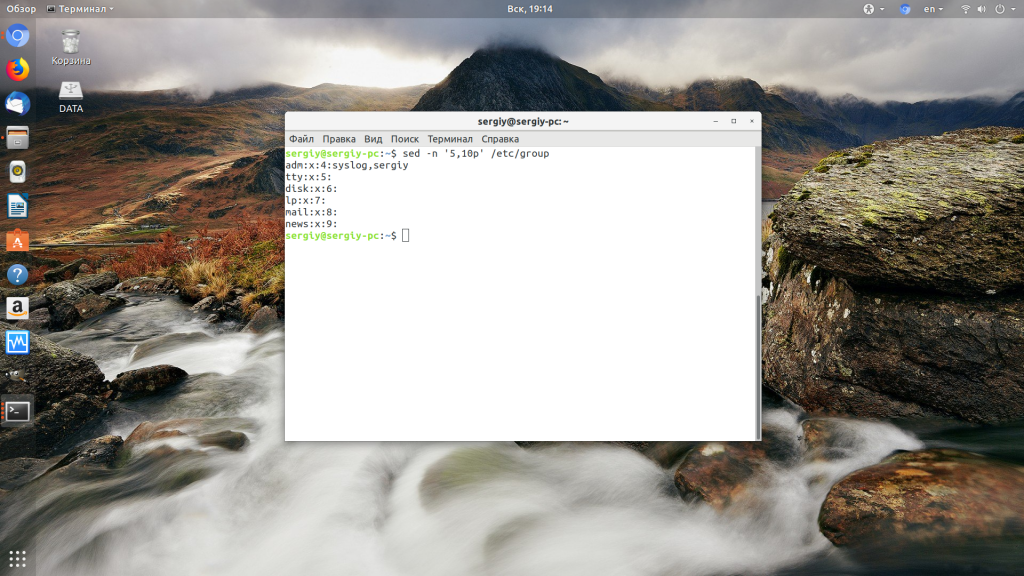
Или можно вывести весь файл, кроме строк с первой по двадцатую:

Здесь наоборот, опцию -n не указываем, чтобы выводилось всё, а с помощью команды d очищаем ненужное. Дальше рассмотрим замену в sed. Это самая частая функция, которая применяется вместе с этой утилитой. Заменим вхождения слова root на losst в том же файле и выведем всё в стандартный вывод:
sed ‘s/root/losst/g’ /etc/group

Флаг g заменяет все вхождения, также можно использовать флаг i, чтобы сделать регулярное выражение sed не зависимым от регистра. Для команд можно задавать адреса. Например, давайте выполним замену 0 на 1000, но только в строках с первой по десятую:
sed ‘1,10 s/0/1000/g’ /etc/group

Переходим ещё ближе к регулярным выражением, удалим все пустые строки или строи с комментариями из конфига Apache:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Под это регулярное выражение (адрес) подпадают все строки, которые начинаются с #, пустые, или начинаются с пробела, а за ним идет решетка. Регулярные выражения можно использовать и при замене. Например, заменим все вхождения p в начале строки на losst_p:
sed ‘s/[$p*]/losst_p/g’ /etc/group

Если вам надо записать результат замены в обратно в файл можно использовать стандартный оператор перенаправления вывода > или утилиту tee. Например:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf | sudo tee /etc/apache2/apache2.conf
Также можно использовать опцию -i, тогда утилита не будет выполнять изменения в переданном ей файле:
sudo sed -i ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Если надо сохранить оригинальный файл, достаточно передать опции -i в параметре расширение для файла резервной копии.
Выводы
Из этой статьи вы узнали что представляет из себя команда sed Linux. Как видите, это очень гибкий инструмент, который позволяет делать с текстом очень многое. Он сложный в освоении, но с помощью него очень удобно решать многие задачи редактирования конфигурационных файлов или фильтрации вывода.