Мониторинг производительности Windows Server, настройка оповещений счетчиков PerfMon
В этой статье мы рассмотрим особенности использования встроенных счетчиков производительности Performance Monitor для мониторинга состояния Windows Server. Счетчики PerfMon можно использовать для отслеживания изменений определенных параметров производительности сервера (алертов) и оповещать администратора в случае возникновения высокой загрузки или других нештатных состояниях.
Чаще всего для мониторинга работоспособности, доступности, загруженности серверов используются сторонние продукты. Если вам нужно получать информацию о производительности приложений либо железа только с одного-двух Windows-серверов, либо когда это нужно на непостоянной основе, либо возник более сложный случай, требующий глубокого траблшутинга производительности, то можно воспользоваться встроенным функционалом Windows Performance Monitor.
Основные возможности Performance Monitor, которые можно использовать отдельно или совместно с другими сторонними системами мониторинга (типа Zabbix, Nagios, Cacti и другие):
- cистема мониторинга при выводе информации о производительности сначала обращается к Performance Monitor;
- главной задачей системы мониторинга является оповещение о наступлении тревожного момента, аварии, а у Performance Monitor – собрать и предоставить диагностические данные.
Текущие значения производительности Windows можно получить из Task Manager, но Performance Monitor умеет несколько больше:
- Task Manager работает только в реальном времени и только на конкретном (локальном) хосте;
- в Performance Monitor можно подключать счётчики с разных серверов, вести наблюдение длительное время и собранную информацию сохранять в файл;
- в Task Manager очень мало показателей производительности.
Мониторинг производительности процессора с Perfomance Monitor
Для снятия данных о производительности процессора воспользуемся несколькими основными счётчиками:
- \Processor\% Processor Time— определяет уровень загрузки ЦП, и отслеживает время, которое ЦП затрачивает на работу процесса. Уровень загрузки ЦП в диапазоне в пределах 80-90 % может указывать на необходимость добавления процессорной мощности.
- \Processor\%Privileged Time — соответствует проценту процессорного времени, затраченного на выполнение команд ядра операционной системы Windows, таких как обработка запросов ввода-вывода SQL Server. Если значение этого счетчика постоянно высокое, и счетчики для объекта Физический диск также имеют высокие значения, то необходимо рассмотреть вопрос об установке более быстрой и более эффективной дисковой подсистемы (см. более подробную статью об анализе производительности дисков с помощью PerfMon).
- \Processor\%User Time — соответствует проценту времени работы CPU, которое он затрачивает на выполнение пользовательских приложений.
Запустите Performance Monitor с помощью команды perfmon. В разделе Performance Monitor отображается загрузкой CPU в реальном времени с помощью графика (параметр Line), с помощью цифр (параметр Report), с помощью столбчатой гистограммы (параметр Histogram bar) (вид выбирается в панели инструментов). Чтобы добавить счетчики, нажмите кнопку “+” (Add Counters).
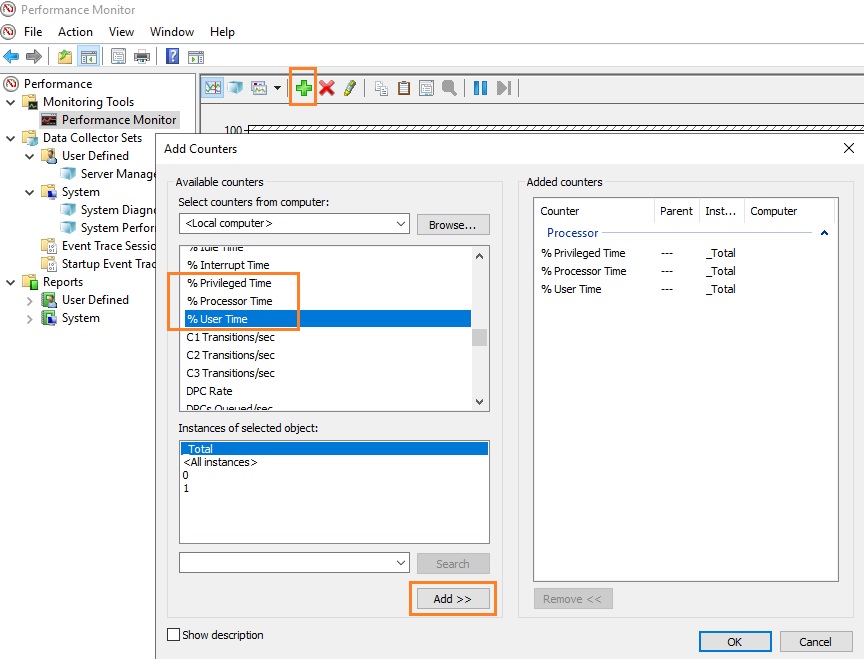
Слева направо двигается линия в реальном времени и отображает график загрузки процессора, на котором можно увидеть, как всплески, так и постоянную нагрузку.
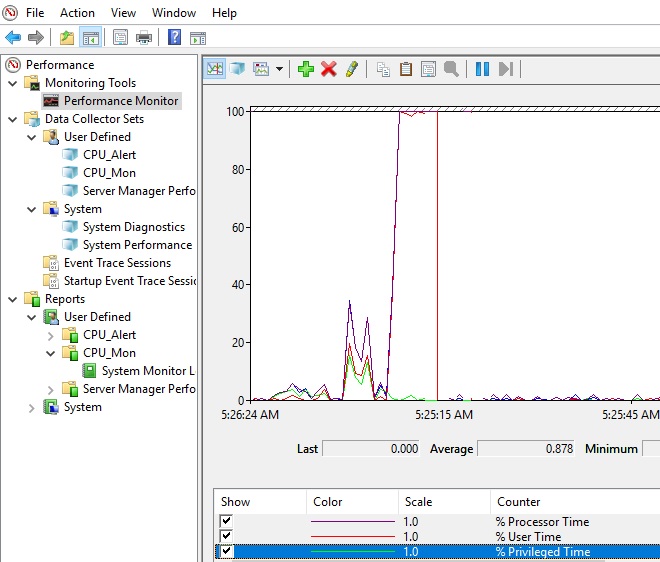
Например, вам нужно посмотреть загрузку процессора виртуальными машинами и самим Hyper-V. Выберите группу счетчиков Hyper-V Hypervisor Logical Processor, выберите счетчик % Total Run Time. Вы можете показывать нагрузку по всем ядрам CPU (Total), либо по конкретным (HV LP №), либо всё сразу (All Instances). Выберем Total и All Instances.
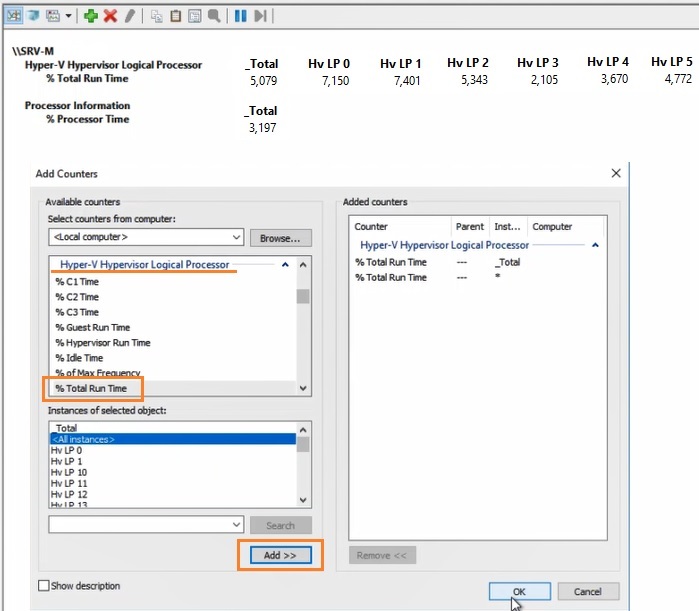
Группы сборщиков данных в PerfMon
Чтобы не сидеть целый за наблюдением движения линии, создаются группы сбор данных (Data Collector Set), задаются для них параметры и периодически просматриваются.
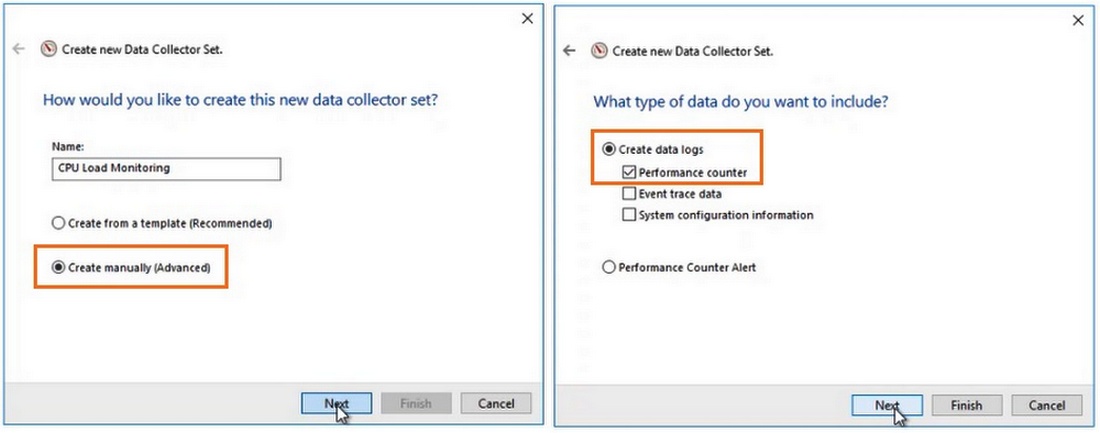
Чтобы создать группу сбора данных, нужно нажать на разделе User Defined правой кнопкой мыши, в меню выбрать New -> Data Collector Set. Выберите Create manually (Advanced) -> Create Data Logs и включите опцию Performance Counter. Нажмите Add и добавите счётчики. В нашем примере % Total Run Time из группы Hyper-V Hypervisor Logical Processor и Available MBytes из Memory. Установите интервал опроса счётчиков в 3 секунды.
Далее вручную запустите созданный Data Collector Set, нажав на нём правой кнопкой мыши и выбрав в меню пункт Start.
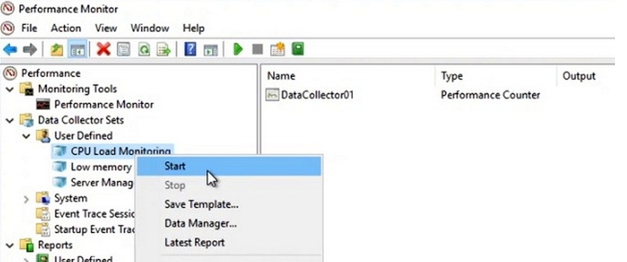
Через некоторое время можно просмотреть отчёт. Для этого в контекстном меню группы сбора данных нужно выбрать пункт Latest Report. Вы можете посмотреть и проанализировать отчёт производительности в виде графика. Отчёт можно скопировать и переслать. Он хранится в C:\PerfLogs\Admin\CPU_Mon и имеет расширение .blg.
Если нужно на другом сервере запустить такой же набор счётчиков, как на первом, то их можно переносить экспортом. Для этого в контекстном меню группы сбора данных выберите пункт Save Template, укажите имя файла (расширение .xml). Скопируйте xml файл на другой сервер, создайте новую группу сбора данных, выберите пункт Create from a template и укажите готовый шаблон.
Создание Alert для мониторинга загрузки CPU
В определённый критический момент в Performance Monitor могут срабатывать алерты, которые помогают ИТ-специалисту прояснить суть проблемы. В первом случае алерт может отправить оповещение, а во втором – запустить другую группу сбора данных.
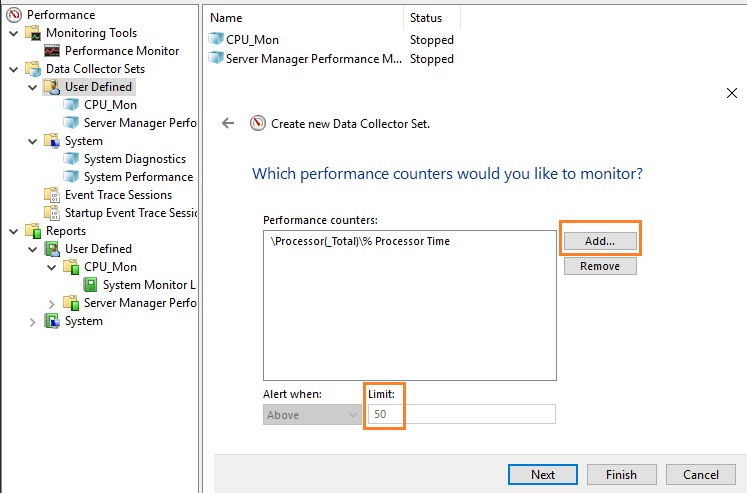
Чтобы создать алерт в PerfMon, нужно создать ещё один Data Collector Set. Укажите его имя CPU_Alert, выберите опцию Create manually (Advanced), а затем — Performance Counter Alert. Добавьте счётчик % Total Run Time из Hyper-V Hypervisor Logical Processor, укажите границу загрузки 50 %, при превышении которой будет срабатывать алерт, установите интервал опроса счётчика в 3 секунды.
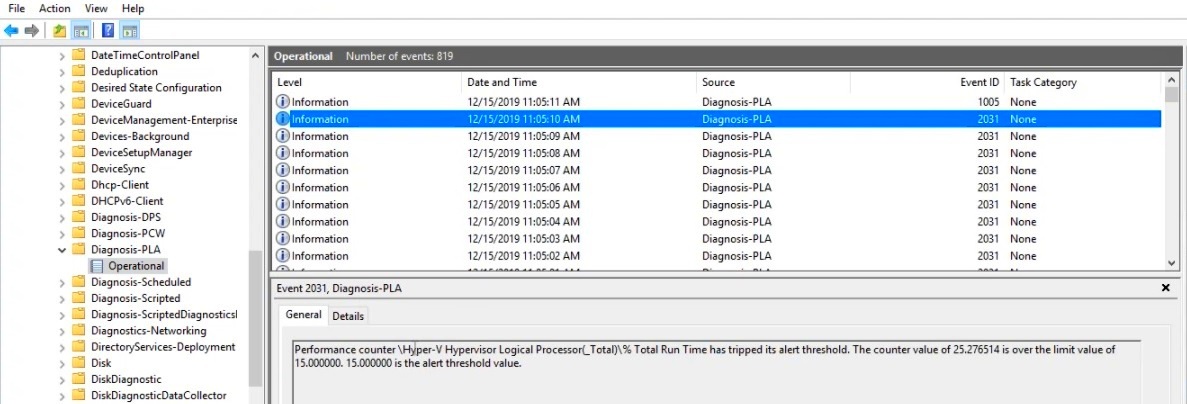
Далее нужно зайти в свойства данной группы сбора информации, перейти на вкладку Alert Action, включить опцию Log an entry in the application event log и запустить группу сбора данных. Когда сработает алерт, в журнале (в консоли Event Viewer в разделе Applications and Services Logs\Microsoft\Windows\Diagnosis-PLA\Operational) появится запись:
“Performance counter \Processor(_Total)\% Processor Time has tripped its alert threshold. The counter value of 100.000000 is over the limit value of 50.000000. 50.000000 is the alert threshold value”.
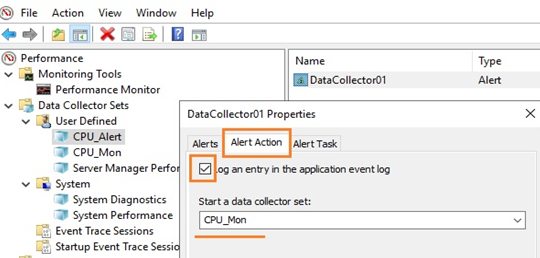
Здесь же рассмотрим и второй случай, когда нужно запустить другую группу сбора данных. Например, алерт срабатывает при достижении высокой загрузки CPU, делает запись в лог, но вы хотите включить сбор данных с других счётчиков для получения дополнительной информации. Для этого необходимо в свойствах алерта в меню Alert Action в выпадающем списке Start a data collector set выбрать ранее созданную группу сбора, например, CPU_Mon. Рядом находится вкладка Alert Task, в которой можно указать разные аргументы либо подключить готовую задачу из консоли Task Scheduler, указав её имя в поле Run this task when an alert is triggered. Будем использовать второй вариант.
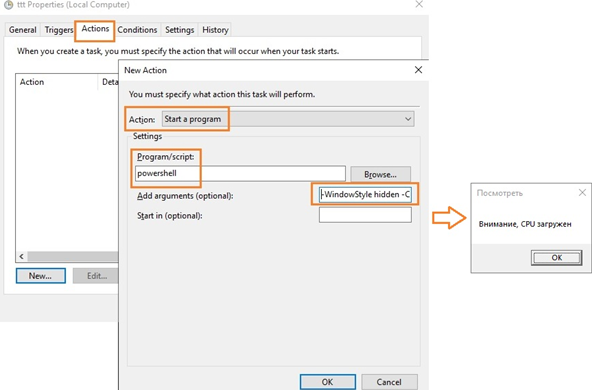
С помощью Task Scheduler можно выполнить какие-то действия: выполнить команду, отправить письмо или вывести сообщение на экран (сейчас последниед ве функции не поддерживаются, считаются устаревшими (deprecated)). Для вывода на уведомления на экран можно использовать скриптом PowerShell. Для этого в консоли Task Scheduler создайте новую задачу, на вкладке Triggers выберите One time, на вкладке Actions в выпадающем поле Action выбирите параметр Start a program, в поле Program/Script укажите powershell.exe, а в поле Add arguments (optional) следующий код:
-WindowStyle hidden -Command «& <[System.Reflection.Assembly]::LoadWithPartialName('System.Windows.Forms'); [System.Windows.Forms.MessageBox]::Show('Внимание, CPU загружен', 'Посмотреть')>«
Для отправки письма вы можете воспользоваться командлетом PowerShell Send-MailMessage или стороннюю утилиту mailsend.exe.. Для этого создайте аналогичное задание в Task Scheduler, в поле Program/Script укажите полный путь к утилите (у нас C:\Scripts\Mail\mailsend.exe), а в поле Add arguments (optional) через параметры нужно передать значения: электронный адрес, адрес и номер порта SMTP-сервера, текст письма и заголовка, пароль:
-to dep.it@ddd.com -from dep.it@ddd.com -ssl -port 465 -auth -smtp smtp.ddd.com -sub Alarm -v -user dep.it@ddd.com +cc +bc -M «Alarm, CPU, Alarm» -pass «it12345»
где +cc означает не запрашивать копию письма, +bc — не запрашивать скрытую копию письма.
Сравнение систем мониторинга серверов
Как вы уже догадались, в данной статье речь пойдёт о системах мониторинга для серверов. Мониторинг серверов является неотъемлемой частью бесперебойной и успешной работы инфраструктуры. Он помогает оперативно среагировать на возникающие проблемы. Каждый инженер, работающий с серверами просто обязан уметь поднимать систему мониторинга.
Итак, рассмотрим наиболее популярные и информативные системы мониторинга серверов и не только.
1. Zabbix
Профессиональная, весьма информативная система мониторинга серверов, коммутаторов и тд. Умеет практически всё — отсылает уведомления на почту и в мессенджеры (скриптами). Огромнейшее количество триггеров, может показывать всё что нужно профессиональному системному-админу. Использую эту систему около года, полёт нормальный, но тяжела для освоения.
- Широкие возможности мониторинга
- Множество триггеров, вплоть до температуры устройства
- Кроссплатформенность (Windows/Unix/Linux системы)
- Отправка данных на mail и в мессенджеры (slack, telegram)
- Бесплатный
- Высокие требования к аппаратной части, большая нагрузка
- Туговат в освоении, новичкам будет тяжеловато настроить
- Требует установки агента непосредственно на каждом сервере
2. Nagios
Аналог Zabbix, который имеет практически все те же функции, производит мониторинг посредством плагинов в отличии от Zabbix, который требует установки своего агента на всех серверах.
- Легко настраивается
- Большое обилие плагинов
- Бесплатный
- Не умеет мониторить производительность
- Конфигурируется в терминале
- Много процессов (на каждый плагин — отдельный процесс)
3. PRTG Network Monitor
На мой взгляд один из удобнейших и достойных мониторингов. Не требует особой настройки серверов, которые будут мониторится. Умеет сам собирать всю информацию о вашей сети и рисовать Дашборд. Есть один весомый недостаток — встаёт только на Windows, но на любой. Также отличный редактор карт сети, который поможет нарисовать карту топологии со связями.
- Предельно прост в установке
- Самостоятельно умеет собирать информацию о сети
- Разберётся даже неопытный сисадмин
- Не требует каких либо установок на стороне серверов кроме настройки файрволла
- Рисует удобные и легкочитаемые графики
- Встает только на Windows
- Платный
4. Cacti
Простой в освоении и настройке инструмент для мониторинга сети и серверов. Сочетает в себе огромное количество графиков, которые умеет рисовать. Для добавления графика достаточно выбрать шаблон.
- Прост в освоении и развертке
- Не требователен к ресурсам
- Также не нужно устанавливать ничего кроме настройки файрволла
- Куча графиков для детального мониторинга
- На мой взгляд не очень презентабельный дашборд
- Морально устаревший мониторинг
Мы рассмотрели наиболее популярные системы мониторинга, какую из них использовать, решать вам.
Спасибо за внимание! Подписывайтесь на мой канал, будет интересно!
7 бесплатных программ для мониторинга сети и серверов
Мантра мира недвижимости — Местоположение, Местоположение, Местоположение. Для мира системного администрирования этот священный текст должен звучать так: Видимость, Видимость и еще раз Видимость. Если каждую секунду на протяжении всего дня вы досконально не знаете, что делают ваша сеть и сервера, вы похожи на пилота, который летит вслепую. Вас неминуемо ждет катастрофа. К счастью для вас, на рынке сейчас доступно много хороших программ, как коммерческих, так и с открытым исходным кодом, способных наладить ваш сетевой мониторинг.

Поскольку хорошее и бесплатное всегда заманчивее хорошего и дорогого, предлагаем вам список программ с открытым исходным кодом, которые каждый день доказывают свою ценность в сетях любого размера. От обнаружения устройств, мониторинга сетевого оборудования и серверов до выявления тенденций в функционировании сети, графического представления результатов мониторинга и даже создания резервных копий конфигураций коммутаторов и маршрутизаторов — эти семь бесплатных утилит, скорее всего, смогут приятно удивить вас.
Cacti
Сначала был MRTG (Multi Router Traffic Grapher) — программа для организации сервиса мониторинга сети и измерения данных с течением времени. Еще в 1990-х, его автор Тобиас Отикер (Tobias Oetiker) счел нужным написать простой инструмент для построения графиков, использующий кольцевую базу данных, изначально используемый для отображения пропускной способности маршрутизатора в локальной сети. Так MRTG породил RRDTool, набор утилит для работы с RRD (Round-robin Database, кольцевой базой данных), позволяющий хранить, обрабатывать и графически отображать динамическую информацию, такую как сетевой трафик, загрузка процессора, температура и так далее. Сейчас RRDTool используется в огромном количестве инструментов с открытым исходным кодом. Cacti — это современный флагман среди программного обеспечения с открытым исходным кодом в области графического представления сети, и он выводит принципы MRTG на принципиально новый уровень.
От использования диска до скорости вентилятора в источнике питания, если показатель можно отслеживать, Cacti сможет отобразить его и сделать эти данные легкодоступными.
Cacti — это бесплатная программа, входящее в LAMP-набор серверного программного обеспечения, которое предоставляет стандартизированную программную платформу для построения графиков на основе практически любых статистических данных. Если какое-либо устройство или сервис возвращает числовые данные, то они, скорее всего, могут быть интегрированы в Cacti. Существуют шаблоны для мониторинга широкого спектра оборудования — от Linux- и Windows-серверов до маршрутизаторов и коммутаторов Cisco, — в основном все, что общается на SNMP (Simple Network Management Protocol, простой протокол сетевого управления). Существуют также коллекции шаблонов от сторонних разработчиков, которые еще больше расширяют и без того огромный список совместимых с Cacti аппаратных средств и программного обеспечения.
Несмотря на то, что стандартным методом сбора данных Cacti является протокол SNMP, также для этого могут быть использованы сценарии на Perl или PHP. Фреймворк программной системы умело разделяет на дискретные экземпляры сбор данных и их графическое отображение, что позволяет с легкостью повторно обрабатывать и реорганизовывать существующие данные для различных визуальных представлений. Кроме того, вы можете выбрать определенные временные рамки и отдельные части графиков просто кликнув на них и перетащив.
Так, например, вы можете быстро просмотреть данные за несколько прошлых лет, чтобы понять, является ли текущее поведение сетевого оборудования или сервера аномальным, или подобные показатели появляются регулярно. А используя Network Weathermap, PHP-плагин для Cacti, вы без чрезмерных усилий сможете создавать карты вашей сети в реальном времени, показывающие загруженность каналов связи между сетевыми устройствами, реализуемые с помощью графиков, которые появляются при наведении указателя мыши на изображение сетевого канала. Многие организации, использующие Cacti, выводят эти карты в круглосуточном режиме на 42-дюймовые ЖК-мониторы, установленные на стене, позволяя ИТ-специалистам мгновенно отслеживать информацию о загруженности сети и состоянии канала.
Таким образом, Cacti — это инструментарий с обширными возможностями для графического отображения и анализа тенденций производительности сети, который можно использовать для мониторинга практически любой контролируемой метрики, представляемой в виде графика. Данное решение также поддерживает практически безграничные возможности для настройки, что может сделать его чересчур сложным при определенных применениях.
Nagios
Nagios — это состоявшаяся программная система для мониторинга сети, которая уже многие годы находится в активной разработке. Написанная на языке C, она позволяет делать почти все, что может понадобится системным и сетевым администраторам от пакета прикладных программ для мониторинга. Веб-интерфейс этой программы является быстрым и интуитивно понятным, в то время его серверная часть — чрезвычайно надежной.
Nagios может стать проблемой для новичков, но довольно сложная конфигурация также является преимуществом этого инструмента, так как он может быть адаптирован практически к любой задаче мониторинга.
Как и Cacti, очень активное сообщество поддерживает Nagios, поэтому различные плагины существуют для огромного количества аппаратных средств и программного обеспечения. От простейших ping-проверок до интеграции со сложными программными решениями, такими как, например, написанным на Perl бесплатным программным инструментарием WebInject для тестирования веб-приложений и веб сервисов. Nagios позволяет осуществлять постоянный мониторинг состояния серверов, сервисов, сетевых каналов и всего остального, что понимает протокол сетевого уровня IP. К примеру, вы можете контролировать использование дискового пространства на сервере, загруженность ОЗУ и ЦП, использования лицензии FLEXlm, температуру воздуха на выходе сервера, задержки в WAN и Интеренет-канале и многое другое.
Очевидно, что любая система мониторинга серверов и сети не будет полноценной без уведомлений. У Nagios с этим все в порядке: программная платформа предлагает настраиваемый механизм уведомлений по электронной почте, через СМС и мгновенные сообщения большинства популярных Интернет-мессенджеров, а также схему эскалации, которая может быть использована для принятия разумных решений о том, кто, как и при каких обстоятельствах должен быть уведомлен, что при правильной настройке поможет вам обеспечить многие часы спокойного сна. А веб-интерфейс может быть использован для временной приостановки получения уведомлений или подтверждения случившейся проблемы, а также внесения заметок администраторами.
Кроме того, функция отображения демонстрирует все контролируемые устройства в логическом представлении их размещения в сети, с цветовым кодированием, что позволяет показать проблемы по мере их возникновения.
Недостатком Nagios является конфигурация, так как ее лучше всего выполнять через командную строку, что значительно усложняет обучение новичков. Хотя люди, знакомые со стандартными файлами конфигурации Linux/Unix, особых проблем испытать не должны.
Возможности Nagios огромны, но усилия по использованию некоторых из них не всегда могут стоить затраченных на это усилий. Но не позволяйте сложностям запугать вас: преимущества системы раннего предупреждения, предоставляемые этим инструментом для столь многих аспектов сети, сложно переоценить.
Icinga
Icinga начиналась как ответвление от системы мониторинга Nagios, но недавно была переписана в самостоятельное решение, известное как Icinga 2. На данный момент обе версии программы находятся в активной разработке и доступны к использованию, при этом Icinga 1.x совместима с большим количеством плагинами и конфигурацией Nagios. Icinga 2 разрабатывалась менее громоздкой, с ориентацией на производительность, и более удобной в использовании. Она предлагает модульную архитектуру и многопоточный дизайн, которых нет ни в Nagios, ни в Icinga 1.
Icinga предлагает полноценную программную платформу для мониторинга и системы оповещения, которая разработана такой же открытой и расширяемой, как и Nagios, но с некоторыми отличиями в веб-интерфейсе.
Как и Nagios, Icinga может быть использована для мониторинга всего, что говорит на языке IP, настолько глубоко, насколько вы можете использовать SNMP, а также настраиваемые плагины и дополнения.
Существует несколько вариаций веб-интерфейса для Icinga, но главным отличием этого программного решения для мониторинга от Nagios является конфигурация, которая может быть выполнена через веб-интерфейс, а не через файлы конфигурации. Для тех, кто предпочитает управлять своей конфигурацией вне командной строки, эта функциональность станет настоящим подарком.
Icinga интегрируется со множеством программных пакетов для мониторинга и графического отображения, таких как PNP4Nagios, inGraph и Graphite, обеспечивая надежную визуализацию вашей сети. Кроме того, Icinga имеет расширенные возможности отчетности.
Если вам когда-либо приходилось для поиска устройств в вашей сети подключаться через протокол Telnet к коммутаторам и выполнять поиск по MAC-адресу, или вы просто хотите, чтобы у вас была возможность определить физическое местоположение определенного оборудования (или, что, возможно, еще более важно, где оно было расположено ранее), тогда вам будет интересно взглянуть на NeDi.
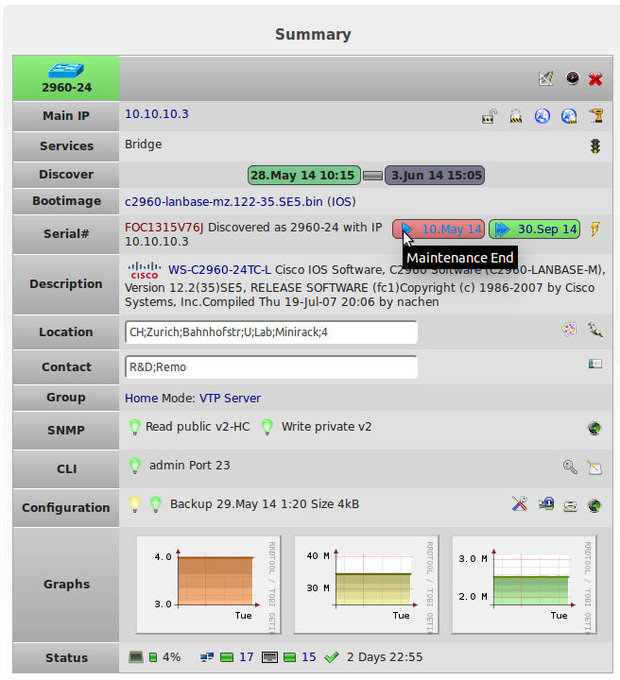
NeDi постоянно просматривает сетевую инфраструктуру и каталогизирует устройства, отслеживая все, что обнаружит.
NeDi — это бесплатное программное обеспечение, относящее к LAMP, которое регулярно просматривает MAC-адреса и таблицы ARP в коммутаторах вашей сети, каталогизируя каждое обнаруженное устройство в локальной базе данных. Данный проект не является столь хорошо известным, как некоторые другие, но он может стать очень удобным инструментом при работе с корпоративными сетями, где устройства постоянно меняются и перемещаются.
Вы можете через веб-интерфейс NeDi задать поиск для определения коммутатора, порта коммутатора, точки доступа или любого другого устройства по MAC-адресу, IP-адресу или DNS-имени. NeDi собирает всю информацию, которую только может, с каждого сетевого устройства, с которым сталкивается, вытягивая с них серийные номера, версии прошивки и программного обеспечения, текущие временные параметры, конфигурации модулей и т. д. Вы даже можете использовать NeDi для отмечания MAC-адресов устройств, которые были потеряны или украдены. Если они снова появятся в сети, NeDi сообщит вам об этом.
Обнаружение запускается процессом cron с заданными интервалами. Конфигурация простая, с единственным конфигурационным файлом, который позволяет значительно повысить количество настроек, в том числе возможность пропускать устройства на основе регулярных выражений или заданных границ сети. NeDi, обычно, использует протоколы Cisco Discovery Protocol или Link Layer Discovery Protocol для обнаружения новых коммутаторов и маршрутизаторов, а затем подключается к ним для сбора их информации. Как только начальная конфигурация будет установлена, обнаружение устройств будет происходить довольно быстро.
До определенного уровня NeDi может интегрироваться с Cacti, поэтому существует возможность связать обнаружение устройств с соответствующими графиками Cacti.
Проект Ntop — сейчас для «нового поколения» более известный как Ntopng — прошел долгий путь развития за последнее десятилетие. Но назовите его как хотите — Ntop или Ntopng, — в результате вы получите первоклассный инструмент для мониторинга сетевого траффика в паре с быстрым и простым веб-интерфейсом. Он написан на C и полностью самодостаточный. Вы запускаете один процесс, настроенный на определенный сетевой интерфейс, и это все, что ему нужно.
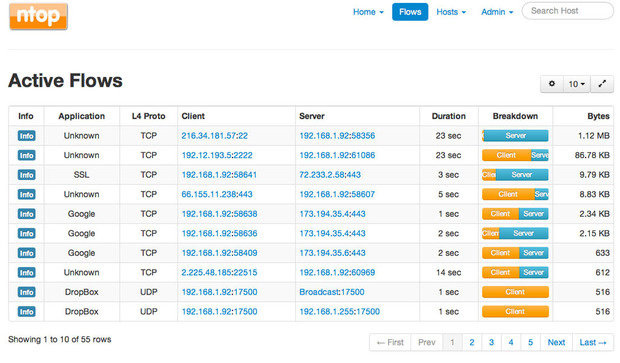
Ntop — это инструмент для анализа пакетов с легким веб-интерфейсом, который показывает данные в реальном времени о сетевом трафике. Информация о потоке данных через хост и о соединении с хостом также доступны в режиме реального времени.
Ntop предоставляет легко усваиваемые графики и таблицы, показывающие текущий и прошлый сетевой трафик, включая протокол, источник, назначение и историю конкретных транзакций, а также хосты с обоих концов. Кроме того, вы найдете впечатляющий набор графиков, диаграмм и карт использования сети в реальном времени, а также модульную архитектуру для огромного количества надстроек, таких как добавление мониторов NetFlow и sFlow. Здесь вы даже сможете обнаружить Nbox — аппаратный монитор, который встраивает в Ntop.
Кроме того, Ntop включает API-интерфейс для скриптового языка программирования Lua, который может быть использован для поддержки расширений. Ntop также может хранить данные хоста в файлах RRD для осуществления постоянного сбора данных.
Одним из самых полезных применений Ntopng является контроль трафика в конкретном месте. К примеру, когда на вашей карте сети часть сетевых каналов подсвечены красным, но вы не знаете почему, вы можете с помощью Ntopng получить поминутный отчет о проблемном сегменте сети и сразу узнать, какие хосты ответственны за проблему.
Пользу от такой видимости сети сложно переоценить, а получить ее очень легко. По сути, вы можете запустить Ntopng на любом интерфейсе, который был настроен на уровне коммутатора, для мониторинга другого порта или VLAN. Вот и все.
Zabbix
Zabbix — это полномасштабный инструмент для сетевого и системного мониторинга сети, который объединяет несколько функций в одной веб-консоли. Он может быть сконфигурирован для мониторинга и сбора данных с самых разных серверов и сетевых устройств, обеспечивая обслуживание и мониторинг производительности каждого объекта.
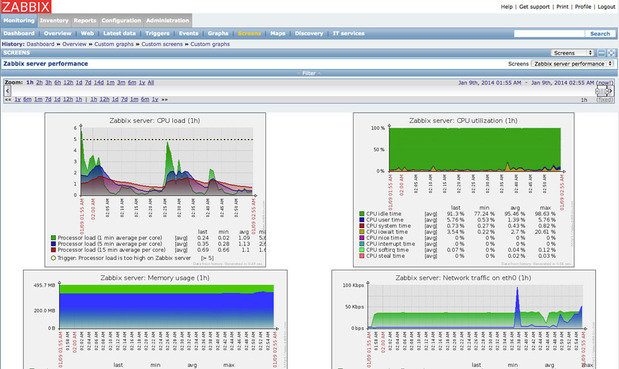
Zabbix позволяет производить мониторинг серверов и сетей с помощью широкого набора инструментов, включая мониторинг гипервизоров виртуализации и стеков веб-приложений.
В основном, Zabbix работает с программными агентами, запущенными на контролируемых системах. Но это решение также может работать и без агентов, используя протокол SNMP или другие возможности для осуществления мониторинга. Zabbix поддерживает VMware и другие гипервизоры виртуализации, предоставляя подробные данные о производительности гипервизора и его активности. Особое внимание также уделяется мониторингу серверов приложений Java, веб-сервисов и баз данных.
Хосты могут добавляться вручную или через процесс автоматического обнаружения. Широкий набор шаблонов по умолчанию применяется к наиболее распространенным вариантам использования, таким как Linux, FreeBSD и Windows-сервера; широко-используемые службы, такие как SMTP и HTTP, а также ICMP и IPMI для подробного мониторинга аппаратной части сети. Кроме того, пользовательские проверки, написанные на Perl, Python или почти на любом другом языке, могут быть интегрированы в Zabbix.
Zabbix позволяет настраивать панели мониторинга и веб-интерфейс, чтобы сфокусировать внимание на наиболее важных компонентах сети. Уведомления и эскалации проблем могут основываться на настраиваемых действиях, которые применяются к хостам или группам хостов. Действия могут даже настраиваться для запуска удаленных команд, поэтому некий ваш сценарий может запускаться на контролируемом хосте, если наблюдаются определенные критерии событий.
Программа отображает в виде графиков данные о производительности, такие как пропускная способность сети и загрузка процессора, а также собирает их для настраиваемых систем отображения. Кроме того, Zabbix поддерживает настраиваемые карты, экраны и даже слайд-шоу, отображающие текущий статус контролируемых устройств.
Zabbix может быть сложным для реализации на начальном этапе, но разумное использование автоматического обнаружения и различных шаблонов может частично облегчить трудности с интеграцией. В дополнение к устанавливаемому пакету, Zabbix доступен как виртуальное устройство для нескольких популярных гипервизоров.
Observium
Observium — это программа для мониторинга сетевого оборудования и серверов, которое имеет огромный список поддерживаемых устройств, использующих протокол SNMP. Как программное обеспечение, относящееся к LAMP, Observium относительно легко устанавливается и настраивается, требуя обычных установок Apache, PHP и MySQL, создания базы данных, конфигурации Apache и тому подобного. Он устанавливается как собственный сервер с выделенным URL-адресом.
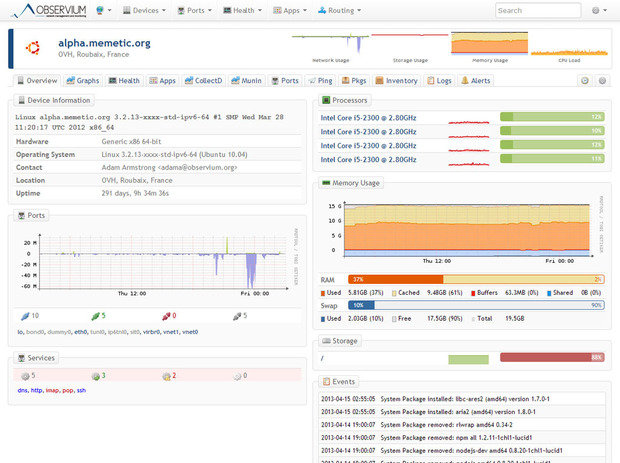
Observium сочетает в себе мониторинг систем и сетей с анализом тенденций производительности. Он может быть настроен для отслеживания практически любых показателей.
Вы можете войти в графический интерфейс и начать добавлять хосты и сети, а также задать диапазоны для автоматического обнаружения и данные SNMP, чтобы Observium мог исследовать окружающие его сети и собирать данные по каждой обнаруженной системе. Observium также может обнаруживать сетевые устройства через протоколы CDP, LLDP или FDP, а удаленные агенты хоста могут быть развернуты на Linux-системах, чтобы помочь в сборе данных.
Все эта собранная информация доступна через легкий в использовании пользовательский интерфейс, который предоставляет продвинутые возможности для статистического отображения данных, а также в виде диаграмм и графиков. Вы можете получить что угодно: от времени отклика ping и SNMP до графиков пропускной способности, фрагментации, количества IP-пакетов и т. д. В зависимости от устройства, эти данные могут быть доступны вплоть для каждого обнаруженного порта.
Что касается серверов, то для них Observium может отобразить информацию о состоянии центрального процессора, оперативной памяти, хранилища данных, свопа, температуры и т. д. из журнала событий. Вы также можете включить сбор данных и графическое отображение производительности для различных сервисов, включая Apache, MySQL, BIND, Memcached, Postfix и другие.
Observium отлично работает как виртуальная машина, поэтому может быстро стать основным инструментом для получения информации о состоянии серверов и сетей. Это отличный способ добавить автоматическое обнаружение и графическое представление в сеть любого размера.
Мониторинг сети своими руками
Слишком часто ИТ-администраторы считают, что они ограничены в своих возможностях. Независимо от того, имеем ли мы дело с пользовательским программным приложением или «неподдерживаемой» частью аппаратного обеспечения, многие из нас считают, что если система мониторинга не сможет сразу же справиться с ним, то получить в этой ситуации необходимые данные невозможно. Это, конечно же, не так. Приложив немного усилий, вы сможете почти все сделать более видимым, учтенным и контролируемым.

В качестве примера можно привести пользовательское приложение с базой данных на серверной части, например, интернет-магазин. Ваш менеджмент хочет увидеть красивые графики и диаграммы, оформленные то в одном виде, то в другом. Если вы уже используете, скажем, Cacti, у вас есть несколько возможностей вывести собранные данные в требуемом формате. Вы можете, к примеру, написать простой скрипт на Perl или PHP для запуска запросов в базе данных и передачи этих расчетов в Cacti либо же использовать SNMP-вызов к серверу базы данных, используя частный MIB (Management Information Base, база управляющей информации). Так или иначе, но задача может быть выполнена, и выполнена легко, если у вас есть необходимый для этого инструментарий.
Получить доступ к большинству из приведенных в данной статье бесплатных утилит для мониторинга сетевого оборудования не должно быть сложно. У них есть пакетные версии, доступные для загрузки для наиболее популярных дистрибутивов Linux, если только они изначально в него не входят. В некоторых случаях они могут быть предварительно сконфигурированы как виртуальный сервер. В зависимости от размера вашей инфраструктуры, конфигурирование и настройка этих инструментов может занять довольно много времени, но как только они заработают, они станут надежной опорой для вас. В крайнем случае, стоит хотя бы протестировать их.
Независимо от того, какую из этих вышеперечисленных систем вы используете, чтобы следить за своей инфраструктурой и оборудованием, она предоставит вам как минимум функциональные возможности еще одного системного администратора. Она хоть не может ничего исправить, но будет следить буквально за всем в вашей сети круглые сутки и семь дней в неделю. Предварительно потраченное время на установку и настройку окупятся с лихвой. Кроме того, обязательно запустите небольшой набор автономных средств мониторинга на другом сервере, чтобы наблюдать за основным средством мониторинга. Это то случай, когда всегда лучше следить за наблюдателем.
Подписывайтесь на рассылку, делитесь статьями в соцсетях и задавайте вопросы в комментариях!