Настройка непрерывного архивирования в PostgreSQL 9.6
Для возможности восстановления кластера СУБД PostgreSQL и его баз данных на момент времени необходимо обеспечить наличие:
- Базовой резервной копии
Следует обратить внимание, что утилиты pg_dump и pg_dumpall создают логическую копию, которая не содержит информации для дальнейшего воспроизведения журнала транзакций и потому не подходит для решения задачи восстановления Point-in-Time.
Наиболее простым способом получения базовой резервной копии является утилита pg_basebackup , создающая копию файловой системы всего кластера.
- Непрерывного архива WAL — журнала транзакций
Наличие непрерывной последовательности архивированных файлов WAL, начинающихся не позднее момента создания файловой резервной копии, позволит после восстановления данных из файловой копии воспроизвести журнал на нужный момент времени и привести систему в состояние на этот момент.
Настройка и выполнение резервного копирования
1 — Включаем архивирование WAL на уровне сервера.
В конфигурационном файле postgresql.conf меняем настройки:
wal_level = replica
archive_mode = on
archive_command = ‘copy «%p» «C:\\PostgreSQLBackup\\%f»‘
— команда, которая будет выполняться при архивировании WAL в момент переключения на его следующий сегмент. Параметр %p автоматически заменяется полным путём к файлу, подлежащему архивации (. \pg_xlog), а %f — именем файла. C:\PostgreSQLBackup\ в данном примере — путь к директории, куда будет производиться архивирование WAL.
В качестве archive_command может быть также указан скрипт, описывающий более сложную логику операций — архивирование файлов, пакетная передача и др., например:
archive_command = ‘local_backup_script.sh «%p» «%f»‘
В случае, если переключение на следующий сегмент лога и последующее архивирование происходит слишком редко ввиду невысокой интенсивности работы кластера, можно установить значение параметра:
— период в секундах, по достижении которого переключение на новый сегмент произойдет принудительно.
(значение по умолчанию — 0, значение 5 указано в качестве примера и технически может быть любым, отличным от 0)
Необходимо обратить внимание, что в случае, если для кластера существует hot_standby -реплика, которая уже является получателем WAL-архивов, значение параметра max_wal_senders , определяющего количество процессов, выполняющих передачу WAL, должно быть не менее 2.
В конфигурационном файле pg_hba.conf разрешаем пользователю, под которым будет выполняться архивирование, подключение для репликации:
host replication postgres ::1/128 md5
host replication postgres 127.0.0.1/32 md5
Выполняем перезапуск службы сервера.
2 — Приступаем к созданию базовых резервных копий.
Интервал создания копии выбирается индивидуально исходя из того, сколько места на диске может быть выделено для хранения файлов WAL, и их размера — необходимо будет хранить все файлы с момента создания последней резервной копии. Копии в примере будут создаваться с помощью утилиты pg_basebackup (подробно об ее использовании и опциях можно прочитать в документации PostgreSQL https://www.postgresql.org/docs/9.6/static/app-pgbasebackup.html). Выполнять резервное копирование можно без остановки работы кластера, однако процесс может привести к повышенной нагрузке на CPU и дисковую подсистему, поэтому лучше делать это в периоды с наименьшей нагрузкой.
Если для кластера включена hot_standby-реплика, лучше использовать именно её для создания резервных копий, чтобы не нагружать master-сервер. Алгоритм выполнения на ведомом сервере будет таким же, но есть несколько настроек, которые необходимо дополнительно выполнить на slave-сервере (описаны в документации к утилите pg_basebackup ).
pg_basebackup -D «D:\Backup» -X fetch — F tar
-D — директория, куда будет скопировано содержимое каталога ..\data. Она должна быть пустой
-F — формат. В данном примере значение tar означает, что содержимое будет добавлено в архив
-X — метод копирования файлов WAL, созданных в процессе создания копии. Значение fetch означает, что файлы будут скопированы в конце процесса.
Выполнение восстановления
Для выполнения восстановления с использованием полной резервной копии и архива WAL необходимо:
1. Остановить сервер баз данных PostgreSQL.
2. Удалить (а лучше — скопировать во временную директорию) содержимое текущего каталога кластера баз данных (. \data).
3. Восстановить (скопировать) файлы необходимой архивной копии, созданной ранее, в текущий каталог данных кластера (…\data). Файлы WAL в директории \ pg_xlog нужно удалить (или заменить на содержимое каталога, скопированного в п.2)
4. Создать конфигурационный фай recovery.conf. В качестве основы можно взять расположенный обычно в директории …\share файл recovery.conf.sample. В нем необходимо выполнить настройку:
restore_command = ‘copy «C:\\PostgreSQLBackup\\%f» «%p»‘
— команда, которая будет выполняться для получения созданных ранее архивов WAL (действие, обратное выполняемому командой archive_command в postgresql.conf). Важно, чтобы в случае ошибки restore_command возвращала ненулевой код. По аналогии с archive_command, можно указать в качестве команды скрипт с более сложной логикой.
После запуска сервера получение архивов и их воспроизведение (с помощью команды выше) по умолчанию будет выполняться до последнего файла WAL. Если нужно выполнить восстановление на конкретную точку, эту точку нужно указать в файле recovery.conf .
Например, для восстановления на момент времени:
recovery_target_time = ‘2018-03-15 12:00:00’
Или для восстановления на именованную точку:
Такую точку можно создать, например, выполнив в контексте любой из баз кластера запрос:
5. Запустить сервер баз данных. Он будет запущен в режиме recovery и начнет процесс восстановления. По завершении сервер переименует файл recovery.conf в recovery.done и начнет работать в обычном режиме, в том числе разрешит подключения к нему. Если на время выполнения проверки после восстановления нужно запретить соединения с сервером, это лучше всего сделать в конфигурационном файле pg_hba.conf.
Обеспечение возможности быстрого возврата системы в состояние «до изменений»
В процессе эксплуатации часто возникает необходимость перед выполнением каких-либо изменений системы обеспечить возможность их быстрой отмены. При этом создание дополнительного полного бэкапа не всегда возможно (например, могут быть ограничены ресурсы файлового хранилища, процесс копирования может занимать слишком длительное время и др.). По сути для корректного возврата системы в требуемый момент времени необходимо, чтобы в точке восстановления все изменения в базе данных были сброшены на диск и выполнился checkpoint — контрольная точка.
Один из самых простых возможных сценариев решения такой задачи предполагает использование функции резервного копирования pg_start_backup() , которая вместе с pg_stop_backup() используется в утилите pg_basebackup , описанной выше, с той разницей, что утилита автоматически выполняет физическое копирование кластера в соответствии с параметрами, а ручной вызов возлагает ответственность за создание копии на администратора системы и позволяет физическое копирование «пропустить».
Перед выполнением изменений системы :
1. Убеждаемся, что архивирование WAL включено.
2. Подключаемся к серверу баз данных в контексте любой из баз и выполняем запрос:
select pg_start_backup(‘our_label’, true);
Первым параметром указываем имя метки, которое потом будем использовать при восстановлении. Второй параметр означает, что checkpoint будет осуществлен как можно скорее независимо от настроек параметра checkpoint_completion_target.
Далее мы как раз должны были бы выполнить копирование каталога данных, но в данном случае это нам не нужно — можно приступить к плановым изменениям. Перед этим целесообразно сделать снимок виртуальной машины — это не требует много ресурсов, но повысит надежность. Кроме того, снимок можно будет быстро развернуть в тестовом контуре, если это потребуется (конечно же, это никак не заменяет регулярные полные бэкапы кластера).
В случае необходимости отката изменений далее действия не будут отличаться от алгоритма восстановления, описанного выше, за тем исключением, что не нужно удалять каталог кластера и копировать на его место резервную копию — достаточно просто запустить сервер в режиме восстановления, указав в файле recovery.conf созданную метку в качестве recovery_target_name .
Если отмену делать не нужно, выводим сервер из режима резервного копирования, выполнив:
Записки IT специалиста
Технический блог специалистов ООО»Интерфейс»
Резервное копирование баз данных PostgreSQL.
 Мы не будем напоминать о важности резервного копирования данных, об этом немало сказано, а поговорим о практической реализации одного из сценариев. Сегодня в фокусе нашего внимания будет популярная бесплатная СУБД PostgreSQL. Актуальности данному вопросу добавляет тот факт, что PostgreSQL активно используется для хранения информационных баз системы 1С:Предприятие.
Мы не будем напоминать о важности резервного копирования данных, об этом немало сказано, а поговорим о практической реализации одного из сценариев. Сегодня в фокусе нашего внимания будет популярная бесплатная СУБД PostgreSQL. Актуальности данному вопросу добавляет тот факт, что PostgreSQL активно используется для хранения информационных баз системы 1С:Предприятие.
В данном материале мы рассмотрим реализацию резервного копирования на примере сервера баз данных для 1С:Предприятия, который мы описывали в данной статье. Также заметим, что всё, о чем пойдет речь ниже одинаково применимо как к платформе Linux, так и к платформе Windows, за незначительными уточнениями.
PostgreSQL, как и любая другая СУБД, имеет богатые возможности по резервному копированию как кластера БД, так и отдельных баз, но основным механизмом управления при этом является командная строка, что может вызвать определенные затруднения. Несмотря на то, что утилита PgAdmin позволяет выполнять основные задачи через графический интерфейс, мы все равно рекомендуем освоить работу с PostgreSQL через командную строку, что позволит вам уверенно чувствовать себя в любой ситуации и открывает широкие возможности по автоматизации.
Итак, в нашем распоряжении имеется сервер СУБД на базе Ubuntu Server, где расположены базы 1С:Предприятия, наша задача обеспечить автоматическое резервное копирование в соответствии с заданными условиями.
Прежде всего настроим авторизацию для СУБД. Так как основные операции должны будут производится из скрипта, то имеет смысл разрешить локальный доступ к СУБД без авторизации. Учитывая, что доступ к серверу БД имеет ограниченный круг лиц и расположен он в периметре сети, безопасность пострадает слабо.
Откроем файл pg_hba.conf, он находится в /var/lib/pgsql/data и приведем к следующему виду строку:
На платформе Windows данный файл находится в C:\Program Files\PostgreSQL\Версия_СУБД\data и строка будет иметь несколько иное содержание:
Для создания резервной копии воспользуемся утилитой pg_dump, которая позволяет создать дамп для указанной БД. Создание дампа происходит без блокирования таблиц и представляет снимок БД на момент выполнения команды. Т.е. вы можете создавать дампы во время работы пользователей, в то время как для создания резервной копии средствами 1С вам нужен монопольный доступ к базе.
Синтаксис pg_dump предельно прост, нам нужно указать имя базы и расположение и название файла дампа. Просмотреть список баз можно командой:
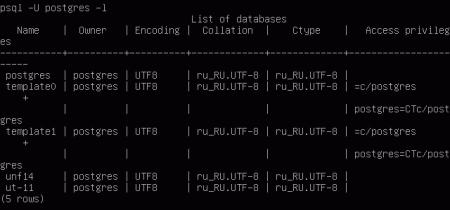 Кроме списка баз вывод содержит ряд полезной информации, например о кодировке базы, данная информация пригодится нам при восстановлении БД на другом сервере.
Кроме списка баз вывод содержит ряд полезной информации, например о кодировке базы, данная информация пригодится нам при восстановлении БД на другом сервере.
Теперь, уточнив наименование баз на сервере создадим резервную копию базы unf14:
результатом выполнения команды будет файл дампа в домашней директории. Расширение файла мы рекомендуем указывать таким образом, чтобы по нему было понятно назначение данного файла и оно может быть любым. В нашем случае мы используем pgsql.backup, глянув на такой файл сразу станет понятно о его назначении, это может быть важно, если поиском дампов будут заниматься ваши коллеги. Также мы не рекомендуем использовать расширение .bak, потому что многие утилиты «для оптимизации» удаляют такие файлы.
При необходимости можем создать сжатый дамп:
Сжатие позволяет уменьшить размер дампов примерно вдвое, поэтому следует его использовать при передаче резервных копий по сети интернет или при ограниченном размере хранилища.
Теперь рассмотрим процедуру восстановления. Для примера будем использовать сервер под управлением Windows. Никаких существенных особенностей по работе с PostgreSQL на разных платформах нет. Однако под Windows следует вместо psql использовать psql.bat и указывать полный путь к утилитам C:\Program Files\PostgreSQL\Версия_СУБД\bin, либо добавить этот путь в системную переменную PATH.
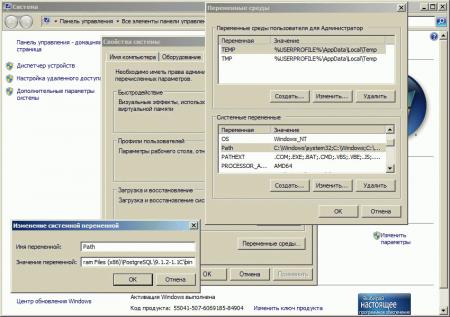 Еще одно важное замечание. Кодировка исходного и целевого серверов должна совпадать, иначе вы после восстановления получите нерабочую базу. На платформе Linux СУБД обычно работает в кодировке UTF8, в то время как сборка PostgreSQL от 1С на Windows по умолчанию устанавливается в кодировке WIN1251.
Еще одно важное замечание. Кодировка исходного и целевого серверов должна совпадать, иначе вы после восстановления получите нерабочую базу. На платформе Linux СУБД обычно работает в кодировке UTF8, в то время как сборка PostgreSQL от 1С на Windows по умолчанию устанавливается в кодировке WIN1251.
Для 1С:Предприятия типичным симптомом того, что вы залили UTF8 базу на сервер с WIN1251 является невозможность авторизоваться в ИБ.
 Перед восстановлением дампа следует создать целевую БД (при ее отсутствии), хотя мы рекомендуем делать это всегда. Еще одна БД есть не просит, зато избавляет от распространенной ситуации, когда залили не тот дамп или не в ту базу. Для создания базы выполним:
Перед восстановлением дампа следует создать целевую БД (при ее отсутствии), хотя мы рекомендуем делать это всегда. Еще одна БД есть не просит, зато избавляет от распространенной ситуации, когда залили не тот дамп или не в ту базу. Для создания базы выполним:
Теперь зальем полученный дамп в только что созданную базу unf14:
На платформе Линукс эта команда будет выглядеть так:
В нашем примере файл дампа находится в C:\backup и домашней директории соответственно.
Все что теперь остается, это через оснастку Администрирование сервера 1С:Предприятия создать новую ИБ или изменить настройки существующей, указав на новый сервер СУБД и новую базу.
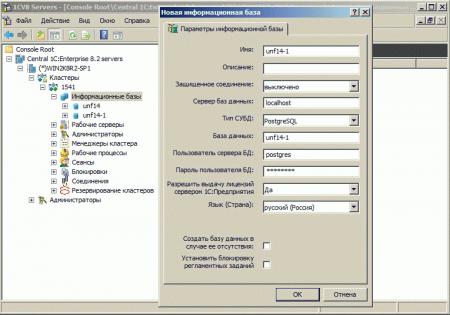
С основными командами мы разобрались и убедились, что ничего сложного в процессе резервного копирования и восстановления баз PostgreSQL нет. Но не будем же мы создавать бекапы вручную. Поэтому перейдем к автоматизации. Создадим скрипт, который будет создавать резервные копии указанных баз и размещать их на FTP-сервере. В силу определенных различий между платформами, создать универсальный скрипт для Windows и Linux не получится, поэтому рассмотрим каждую платформу отдельно.
Начнем с Linux, в нашем случае это Ubuntu Server. Создадим файл скрипта:
и поместим в него следующее содержимое:
Скрипт довольно прост и мы не будем разбирать его подробно. Сохраним его и дадим права на выполнение:
Также не забудем создать каталог /root/backup
Проверив работоспособность скрипта, зададим его регулярное выполнение через cron.
Для платформы Windows все несколько сложнее, так как встроенный архиватор отсутствует, то следует воспользоваться сторонним решением, в нашем случае будет использоваться 7zip, также нужно указывать полные пути к бинарным файлам или добавить их в переменную PATH, мы будем задавать эту переменную динамически в скрипте. Еще одна сложность связана с использованием встроенного ftp-клиента, набор команд для него необходимо подготовить в виде отдельного файла.
Создадим в Блокноте новый файл и разместим там нижеприведенный текст:
Скрипт также довольно прост для понимания и повторяет по структуре и логике скрипт для Ubuntu. Задаем переменные, устанавливаем рабочую директорию и выгружаем туда дамп, затем создаем архив. Следующим шагом формируем файл с командами для FTP-соединения, загружаем архив на FTP и делаем уборку.
Файл следует сохранить как pgsql-backup.bat и разместить в удобном месте. Затем настроить его выполнение по расписанию через Планировщик задач Windows. Также не забудьте создать директорию C:\backup (или любую другою, которую вы хотите использовать в качестве рабочей).
Конечно, наши примеры не затрагиваю все возможные сценарии резервного копирования, но мы уверены что приведенные примеры помогут вам создавать собственные скрипты для автоматизации данного процесса.