Использование UTF-8 в HTTP заголовках

Как известно, HTTP 1.1 — это текстовой протокол передачи данных. HTTP сообщения закодированы, используя ISO-8859-1 (которую условно можно считать расширенной версией ASCII, содержащей умляуты, диакритику и другие символы, используемые в западноевропейских языках). При этом в теле сообщений можно использовать другую кодировку, которая должна быть обозначена в заголовке «Content-Type». Но что делать, если нам необходимо задать non-ASCII символы не в теле сообщения, а в самих заголовках? Наверное, самый распространенный кейс — это проставление имени файла в «Content-Disposition» заголовке. Это, казалось бы, довольно распространенная задача, но ее реализация не так очевидна.
TL;DR: Используйте кодировку, описанную в RFC 6266, для «Content-Disposition» и преобразуйте текст в латиницу (транслит) в остальных случаях.
Небольшая вводная в кодировки
В статье упоминаются и используются кодировки US-ASCII (часто именуемую просто ASCII), ISO-8859-1 и UTF-8. Это небольшая вводная в эти кодировки. Раздел предназначен для разработчиков, которые редко или совсем не работают с кодировками и успели подзабыть их. Если вы к ним не относитесь, то смело пропускайте раздел.
ASCII — это простая кодировка, содержащая 128 символов и включающая весь английский алфавит, цифры, знаки препинания и служебные символы.
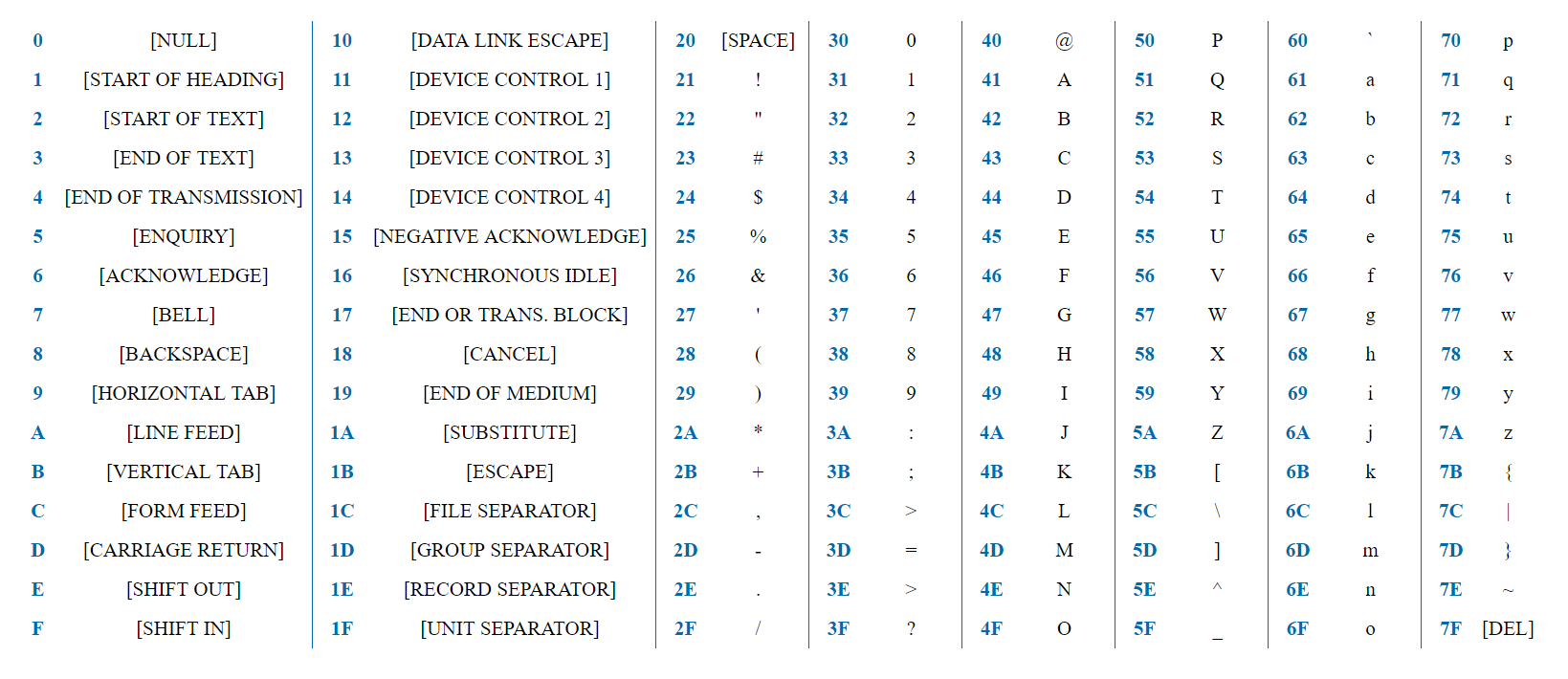
7 бит достаточно, чтобы представить любой ASCII символ. Слово «test» будет представлено в HEX представлении, как 0x74 0x65 0x73 0x74. Первый бит у всех символов всегда 0, поскольку символов в кодировке 128, а байт предоставляет 2^8 = 256 вариантов.
ISO-8859-1 — кодировка, предназначенная для западноевропейских языков. Содержит французскую диакритику, немецкие умляуты и т.д.
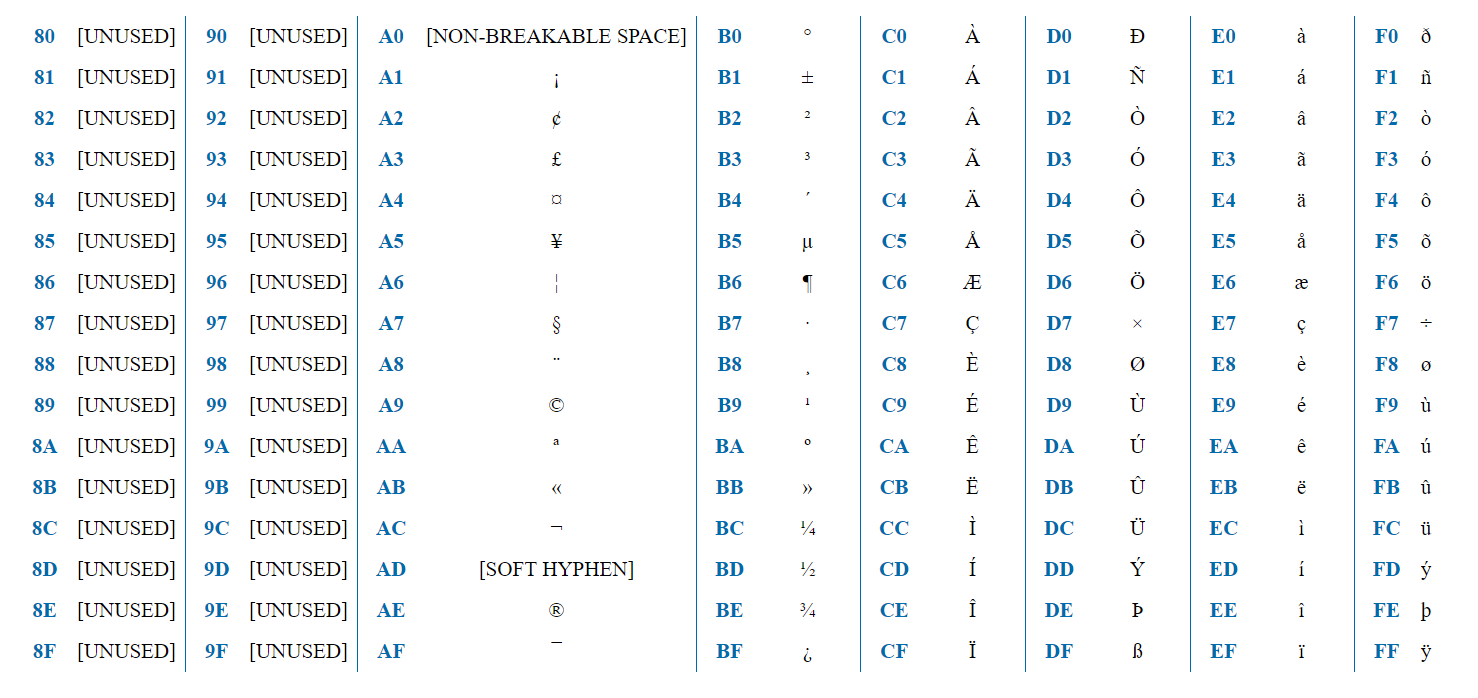
Кодировка содержит 256 символов и, таким образом, может быть представлена одним байтом. Первая половина (128 символов) полностью совпадает с ASCII. Таким образом, если первый бит = 0, то это обычный ASCII символ. Если 1, то это символ, специфичный для ISO-8859-1.
UTF-8 — одна из самых известных кодировок наравне с ASCII. Способна кодировать 1.112.064 символов. Размер каждого символа варьируется от 1-го до 4-х байт (раньше допускались значения до 6 байт).

Программа, работающая с этой кодировкой, определяет по первым битам, как много байтов входит в символ. Если октет начинается с 0, то символ представлен одним байтом. 110 — два байта, 1110 — три байта, 11110 — 4 байта.
Как и в случае с ISO-8859-1, первые 128 символов полностью соответствуют ASCII. Поэтому тексты, использующие только ASCII символы, будут абсолютно идентичны в бинарном представлении, вне зависимости от того, использовалась ли для кодирования US-ASCII, ISO-8859-1 или UTF-8.
Использование UTF-8 в теле сообщения
Прежде чем перейти к заголовкам, давайте быстро взглянем, как использовать UTF-8 в теле сообщений. Для этого используется заголовок «Content-Type».

Если «Content-Type» не задан, то браузер должен обрабатывать сообщения, как будто они написаны в ISO-8859-1. Браузер не должен пытаться отгадать кодировку и, тем более, игнорировать «Content-Type». Но, что реально отобразится в ситуации, когда «Content-Type» не передан, зависит от реализации браузера. Например, Firefox сделает согласно спецификации и прочитает сообщение, будто оно было закодировано в ISO-8859-1. Google Chrome, напротив, будет использовать кодировку операционной системы, которая для многих российских пользователей равна Windows-1251. В любом случае, если сообщение было в UTF-8, то оно будет отображено некорректно.

Проставляем UTF-8 сообщение в значение заголовка
С телом сообщения все достаточно просто. Тело сообщения всегда следует после заголовков, поэтому здесь не возникает технических проблем. Но как быть с заголовками? В спецификации недвусмысленно заявляется, что порядок заголовков в сообщении не имеет значения. Т.е. задать кодировку в одном заголовке через другой заголовок не представляется возможным.
Что будет, если просто взять и записать UTF-8 значение в значение заголовка? Мы видели, что такой трюк с телом сообщения приведет к тому, что значение будет просто прочитано в ISO-8859-1. Логично было бы предположить, что то же самое произойдет с заголовком. Но это не так. Фактически, во многих, если не в большинстве, случаях такое решение будет работать. Сюда включаются старые айфончики, IE11, Firefox, Google Chrome. Единственным из находящихся у меня под рукой браузеров, когда я писал эту статью, который не захотел работать с таким заголовком, является Edge.

Такое поведение не зафиксировано в спецификациях. Возможно, разработчики браузеров решили облегчить жизнь разработчиков и автоматически определять, что в заголовках сообщение закодировано в UTF-8. В общем-то, это не является такой сложной задачей. Смотрим на первый бит: если 0, то ASCII, если 1 — то, возможно, UTF-8.
Нет ли в этом случае пересечения с ISO-8859-1? На самом деле, практически нет. Возьмем для примера UTF-8 символ из 2-х октетов (русские буквы представлены двумя октетами). Символ в бинарном представили будет иметь вид: 110xxxxx 10xxxxxx. В HEX представлении: [0xC0-0x6F] [0x80-0xBF]. В ISO-8859-1 этими символами едва ли можно закодировать что-то, несущее смысловую нагрузку. Поэтому риск того, что браузер неправильно расшифрует сообщение, очень мал.
Однако, при попытке использовать этот способ можно столкнуться с техническими проблемами: ваш веб-сервер или фреймворк может просто не разрешить записывать UTF-8 символы в значение заголовка. Например, Apache Tomcat вместо всех UTF-8 символов проставляет 0x3F (вопросительный знак). Разумеется, это ограничение можно обойти, но, если само приложение бьет по рукам и не дает что-то сделать, то, возможно, вам и не нужно это делать.
Но, независимо от того, разрешает ли вам ваш фреймворк или сервер записать UTF-8 сообщения в заголовок или нет, я не рекомендую этого делать. Это не задокументированное решение, которое в любой момент времени может перестать работать в браузерах.
Транслит
Я думаю, что использовать транслит — eto bolee horoshee reshenie. Многие крупные популярные русские ресурсы не брезгуют использовать транслит в названиях файлов. Это гарантированное решение, которое не сломается с выпуском новых браузеров и которое не надо тестировать отдельно на каждой платформе. Хотя, разумеется, надо подумать, как преобразовывать весь спектр возможных символов, что может быть не совсем тривиально. Например, если приложение рассчитано на российскую аудиторию, то в имя файла могут попасть татарские буквы ә и ң, которые надо как-то обработать, а не просто заменять на «?».
RFC 2047
Как я уже упомянул, томкат не позволил мне проставить UTF-8 в заголовке сообщения. Отражена ли эта особенность поведения в Java docs для сервлетов? Да, отражена:
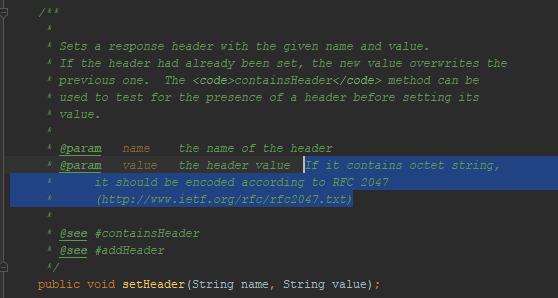
Упоминается RFC 2047. Я пробовал кодировать сообщения, используя этот формат, — браузер меня не понял. Этот метод кодировки не работает в HTTP. Хотя работал раньше. Вот, например, тикет на удаление поддержки этой кодировки из Firefox.
RFC 6266
В тикете, ссылка на который содержится в предыдущем разделе, есть упоминания, что даже после прекращения поддержки RFC 2047, все еще есть способ передавать UTF-8 значения в названии скачиваемых файлов: RFC 6266. На мой взгляд, это самое правильно решение на сегодняшний день. Многие популярные интернет ресурсы используют его. Мы в CUBA Platform также используем именно этот RFC для генерации «Content-Disposition».
RFC 6266 — это спецификация, описывающая использование “Content-Disposition” заголовка. Сам способ кодировки подробно описан в другой спецификации — RFC 8187.

Параметр “filename” содержит название файла в ASCII, “filename*” — в любой необходимой кодировке. При наличии обоих атрибутов “filename” игнорируется во всех современных браузерах (включая IE11 и старые версии Safari). Совсем старые браузеры, напротив, игнорируют “filename*”.
При использовании данного способа кодирования в параметре сначала указывается кодировка, после » идет закодированное значение. Видимые символы из ASCII кодирования не требуют. Остальные символы просто пишутся в hex представлении, со стоящим «%» перед каждым октетом.
Что делать с другими заголовками?
Кодирование, описанное в RFC 8187, не является универсальным. Да, можно поместить в заголовок параметр с * префиксом, и это, возможно, будет даже работать для некоторых браузеров, но спецификация предписывает не делать так.
В каждом случае, где в заголовках поддерживается UTF-8, на настоящий момент есть явное упоминание об этом в релевантном RFC. Помимо «Content-Disposition» данная кодировка используется, например, в Web Linking и Digest Access Authentication.
Следует учесть, что стандарты в этой области постоянно меняются. Использование описанной выше кодировки в HTTP было предложено лишь в 2010. Использование данной кодировки именно в «Content-Disposition» было зафиксировано в стандарте в 2011. Несмотря на то, что эти стандарты находятся лишь на стадии «Proposed Standard», они поддержаны повсеместно. Вариант, что в будущем нас ожидают новые стандарты, которые позволят более унифицировано работать с различными кодировками в заголовках, не исключен. Поэтому остается только следить за новостями в мире стандартов HTTP и уровня их поддержки на стороне браузеров.
Кодировки и веб-страницы
Возвращаясь к избитой проблеме с кодировками русских букв, хотелось бы иметь под рукой некий единый справочник или руководство, в котором можно найти решения различных сходных ситуаций. В своё время сам перелопатил множество статей и публикаций, чтобы находить причины ошибок. Задача этой публикации — сэкономить время и нервы читателя и собрать воедино различные причины ошибок с кодировками в разработке на Java и JSP и способы их устранения.
Варианты решения могут быть не единственными, охотно добавлю предложенные читателем, если они будут рабочими.
Итак, поехали.
1. Проблема: при получении разработанной мной страницы браузером весь русский текст идёт краказябрами, даже тот, который забит статически.
Причина: браузер неверно определяет кодировку текста, потому что нет явного указания.
Решение: явно указать кодировку:
a) HTML: добавляем тэг META в хидер страницы:
б) XML: указываем кодировку в заголовке:
в) JSP — задаём тип контента в заголовке:
г) JSP — задаём кодировку возвращаемой страницы
д) Java — устанавливаем хидер ответа:
2. Проблема: написанный в JSP-странице статический русский текст почему-то идёт краказабрами, хотя кодировка страницы задана.
Причина: статический текст был написан в кодировке, отличной от заданного странице.
Решение: изменить кодировку в редакторе (например, для AkelPad нажимаем «Сохранить как» и выбираем нужную кодировку).
3. Проблема: получаемый из запроса текст идёт кракозябрами.
Причина: кодировка запроса отличается от используемой для его обработки кодировки.
Решение: установить кодировку запроса или перекодировать в нужную.
а) Java, со стороны отправителя не задана нужная кодировка — перекодируем в нужную:
Примечание: кодировка ISO-8859-1 устанавливается по умолчанию, если не была задана другая.
б) Java, со стороны отправителя задана нужная кодировка — устанавливаем кодировку запроса:
4. Проблема: отправленный GET-параметром русский текст при редиректе приходит кракозябрами.
Причина: упаковка русского текста в URI по умолчанию идёт в ISO-8859-1.
Решение: упаковать текст в нужной кодировке вручную.
а) JSP, URLEncoder:
5. Проблема: текст из базы данных читается кракозябрами.
Причина: кодировка текста, прочитанного из базы данных, отличается от кодировки страницы.
Решение: установить соответствующую кодировку страницы, либо перекодировать полученные из базы данных значения.
а) Java, перекодирование считанной в db_string базы данных строки:
6. Проблема: текст записывается в базу данных кракозябрами, хотя на странице отображается правильно.
Причина: кодировка записываемой строки отличается от кодировки сессии работы с базой данных, либо от кодировки базы данных (стоит помнить, что они не всегда совпадают).
Решение: установить необходимую кодировку сессии или перекодировать строку.
а) Java, перекодирование записываемой строки db_string в кодировку сессии или базы данных:
б) Java, MySQL, настройка параметров подключения в строке dburl, передаваемой функции коннекта:
в) MySQL, настройка параметров подключения в XML-описателе контекста, добавляем атрибут к тегу \ :
г) MySQL, прямая установка кодировки сессии вызовом SET NAMES (connect — объект подключения Connection):
7. Проблема: если ничего не помогло…
Решение: всегда остаётся самый «топорный» метод — прямое перекодирование.
а) Для известной кодировки источника:
[String MyValue = new String(source_string.getBytes(«utf-8″),»cp1251»);]
б) Для параметра запроса:
[String MyValue = new String(request.getParameter(«MyParam»).getBytes(request.getCharacterEncoding()),»cp1251″);]
Дополнение, или что нужно знать:
1. Кодировки базы данных и сессии подключения могут различаться, в зависимости от конкретной СУБД и драйвера. К примеру, при подключении к MySQL стандартным драйвером com.mysql.jdbc.Driver без явного указания кодировка сессии устанавливалась в UTF-8, несмотря на другую кодировку схемы БД.
2. Кодировка упаковки строки запроса в URI по умолчанию устанавливается в ISO-8859-1. С подобным можно столкнуться, например, при передаче явно заданного текста в редиректе с одной страницы на другую.
3. Взаимоотношения кодировок страницы, базы данных, сессии, параметров запроса и ответа не зависят от языка разработки и описанные для Java функции имеют аналоги для PHP, Asp и других.
Примечание: восстановить ссылки на источники нет возможности, все примеры взяты из собственного кода, хотя когда-то так же выискивал их по многочисленным форумам.
Надеюсь, этот небольшой обзор поможет начинающим веб-программистам сократить время отладки и сберечь нервы.