Iconv koi8 r windows 1251
Здесь могла бы быть ваша реклама 
Покинул форум
Сообщений всего: 4574
Дата рег-ции: Июль 2006
Откуда: Israel
![]()
Секрет
Теперь, когда вы уже наверняка второпях отправили свой запрос,
я расскажу вам простой секрет, который сэкономит вам уйму ожиданий,
даже если первый ответ по теме последуем сразу же.
Само собой я знаю что ответят мне тут же, и если я посмотрю
на сообщения на форуме, то пойму что в общем то я и не ошибаюсь.
Но еще я точно замечу, что очень мало тем, в которых всего два ответа :
вопрос автора и еще два сообщение вида Ответ + Спасибо
После этого приходится начинать уточнять этим неграмотным что мне надо.
Они что, сами читать не умеют? А уточнять приходится.
И иногда пока они переварят то что я им скажу проходит и не одна ночь..
Уверен что если бы я им сказал что у меня есть
фиолетовый квадрат, и нужно превратить его в синий треугольник
и я пытался взять кисточку, макнуть в банку и поводить ей по квадрату
но почему то кисточка не принимала цвет краски в банке,
то на мой вопрос — где взять правильные банки мне бы ответили гораздо быстрее
предложив её открыть, а не тратить еще стольник на жестянку.
Поэтому с тех пор я строю свои вопросы по проверенной давным давно схеме:
Что есть
Что нужно получить
Как я пытался
Почему или что у меня не получилось.
На последок как оно происходит на форумах
Новичок: Подскажите пожалуста самый крепкий сорт дерева! Весь инет перерыл, поиском пользовался!
Старожил: Объясни, зачем тебе понадобилось дерево? Сейчас оно в строительстве практически не используется.
Новичок: Я небоскрёб собираюсь строить. Хочу узнать, из какого дерева делать перекрытия между этажами!
Старожил: Какое дерево? Ты вообще соображаешь, что говоришь?
Новичок: Чем мне нравиться этот форум — из двух ответов ниодного конкретного. Одни вопросы неподелу!
Старожил: Не нравится — тебя здесь никто не держит. Но если ты не соображаешь, что из дерева небоскрёбы не строят, то лучше бы тебе сначала школу закончить.
Новичок: Не знаите — лучше молчите! У меня дедушка в деревянном доме живёт! У НЕГО НИЧЕГО НЕ ЛОМАЕТСЯ.
Но у него дом из сосны, а я понимаю, что для небоскрёба нужно дерево прочнее! Поэтому и спрашиваю. А от вас нормального ответа недождёшся.
Прохожий: Самое крепкое дерево — дуб. Вот тебе технология вымачивания дуба в солёной воде, она придаёт дубу особую прочность:
Новичок: Спасибо, братан! То что нужно.
Отредактировано модератором: Uchkuma, 26 Апреля, 2011 — 10:21:12

Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:

В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:

Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
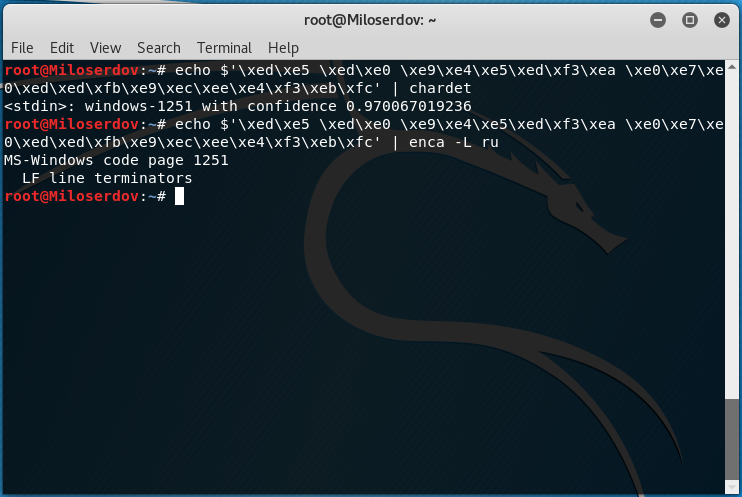
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
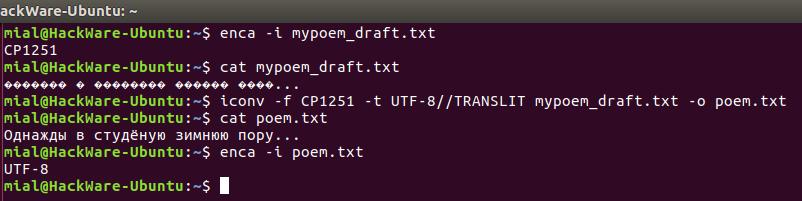
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
iconv
(PHP 4 >= 4.0.5, PHP 5, PHP 7)
iconv — Преобразование строки в требуемую кодировку
Описание
Преобразует набор символов строки str из кодировки in_charset в out_charset .
Список параметров
Кодировка входной строки.
Требуемая на выходе кодировка.
Если добавить к out_charset строку //TRANSLIT , включается режим транслитерации. Это значит, что в случае, если символ не может быть представлен в требуемой кодировке, он будет заменен на один или несколько наиболее близких по внешнему виду символов. Если добавить строку //IGNORE , то символы, которые не могут быть представлены в требуемой кодировке, будут удалены. В случае отсутствия вышеуказанных параметров будет сгенерирована ошибка уровня E_NOTICE , а функция вернет FALSE .
Как будет работат //TRANSLIT и будет ли вообще, зависит от системной реализации iconv() ( ICONV_IMPL ). Известны некоторые реализации, которые просто игнорируют //TRANSLIT , так что конвертация для символов некорректных для out_charset скорее всего закончится ошибкой.
Строка, которую необходимо преобразовать.
Возвращаемые значения
Возвращает преобразованную строку или FALSE в случае возникновения ошибки.
Примеры
Пример #1 Пример использования iconv()
echo ‘Исходная строка : ‘ , $text , PHP_EOL ;
echo ‘С добавлением TRANSLIT : ‘ , iconv ( «UTF-8» , «ISO-8859-1//TRANSLIT» , $text ), PHP_EOL ;
echo ‘С добавлением IGNORE : ‘ , iconv ( «UTF-8» , «ISO-8859-1//IGNORE» , $text ), PHP_EOL ;
echo ‘Обычное преобразование : ‘ , iconv ( «UTF-8» , «ISO-8859-1» , $text ), PHP_EOL ;
Результатом выполнения данного примера будет что-то подобное:
User Contributed Notes 39 notes
The «//ignore» option doesn’t work with recent versions of the iconv library. So if you’re having trouble with that option, you aren’t alone.
That means you can’t currently use this function to filter invalid characters. Instead it silently fails and returns an empty string (or you’ll get a notice but only if you have E_NOTICE enabled).
This has been a known bug with a known solution for at least since 2009 years but no one seems to be willing to fix it (PHP must pass the -c option to iconv). It’s still broken as of the latest release 5.4.3.
[UPDATE 15-JUN-2012]Here’s a workaround.
ini_set(‘mbstring.substitute_character’, «none»);
$text= mb_convert_encoding($text, ‘UTF-8’, ‘UTF-8’);
That will strip invalid characters from UTF-8 strings (so that you can insert it into a database, etc.). Instead of «none» you can also use the value 32 if you want it to insert spaces in place of the invalid characters.
Please note that iconv(‘UTF-8’, ‘ASCII//TRANSLIT’, . ) doesn’t work properly when locale category LC_CTYPE is set to C or POSIX. You must choose another locale otherwise all non-ASCII characters will be replaced with question marks. This is at least true with glibc 2.5.
Example:
( LC_CTYPE , ‘POSIX’ );
echo iconv ( ‘UTF-8’ , ‘ASCII//TRANSLIT’ , «Žluťoučký kůň\n» );
// ?lu?ou?k? k??
setlocale ( LC_CTYPE , ‘cs_CZ’ );
echo iconv ( ‘UTF-8’ , ‘ASCII//TRANSLIT’ , «Žluťoučký kůň\n» );
// Zlutoucky kun
?>
Interestingly, setting different target locales results in different, yet appropriate, transliterations. For example:
//some German
$utf8_sentence = ‘Weiß, Goldmann, Göbel, Weiss, Göthe, Goethe und Götz’ ;
//UK
setlocale ( LC_ALL , ‘en_GB’ );
//transliterate
$trans_sentence = iconv ( ‘UTF-8’ , ‘ASCII//TRANSLIT’ , $utf8_sentence );
//gives [Weiss, Goldmann, Gobel, Weiss, Gothe, Goethe und Gotz]//which is our original string flattened into 7-bit ASCII as
//an English speaker would do it (ie. simply remove the umlauts)
echo $trans_sentence . PHP_EOL ;
//Germany
setlocale ( LC_ALL , ‘de_DE’ );
$trans_sentence = iconv ( ‘UTF-8’ , ‘ASCII//TRANSLIT’ , $utf8_sentence );
//gives [Weiss, Goldmann, Goebel, Weiss, Goethe, Goethe und Goetz]//which is exactly how a German would transliterate those
//umlauted characters if forced to use 7-bit ASCII!
//(because really ä = ae, ö = oe and ü = ue)
echo $trans_sentence . PHP_EOL ;
to test different combinations of convertions between charsets (when we don’t know the source charset and what is the convenient destination charset) this is an example :
= array( «UTF-8» , «ASCII» , «Windows-1252» , «ISO-8859-15» , «ISO-8859-1» , «ISO-8859-6» , «CP1256» );
$chain = «» ;
foreach ( $tab as $i )
<
foreach ( $tab as $j )
<
$chain .= » $i$j » . iconv ( $i , $j , » $my_string » );
>
>
echo $chain ;
?>
then after displaying, you use the $i$j that shows good displaying.
NB: you can add other charsets to $tab to test other cases.
If you are getting question-marks in your iconv output when transliterating, be sure to ‘setlocale’ to something your system supports.
Some PHP CMS’s will default setlocale to ‘C’, this can be a problem.
use the «locale» command to find out a list..
( LC_CTYPE , ‘en_AU.utf8’ );
$str = iconv ( ‘UTF-8’ , ‘ASCII//TRANSLIT’ , «Côte d’Ivoire» );
?>
Like many other people, I have encountered massive problems when using iconv() to convert between encodings (from UTF-8 to ISO-8859-15 in my case), especially on large strings.
The main problem here is that when your string contains illegal UTF-8 characters, there is no really straight forward way to handle those. iconv() simply (and silently!) terminates the string when encountering the problematic characters (also if using //IGNORE), returning a clipped string. The
= html_entity_decode ( htmlentities ( $oldstring , ENT_QUOTES , ‘UTF-8’ ), ENT_QUOTES , ‘ISO-8859-15’ );
?>
workaround suggested here and elsewhere will also break when encountering illegal characters, at least dropping a useful note («htmlentities(): Invalid multibyte sequence in argument in. «)
I have found a lot of hints, suggestions and alternative methods (it’s scary and in my opinion no good sign how many ways PHP natively provides to convert the encoding of strings), but none of them really worked, except for this one:
= mb_convert_encoding ( $oldstring , ‘ISO-8859-15’ , ‘UTF-8’ );
For those who have troubles in displaying UCS-2 data on browser, here’s a simple function that convert ucs2 to html unicode entities :
function ucs2html ( $str ) <
$str = trim ( $str ); // if you are reading from file
$len = strlen ( $str );
$html = » ;
for( $i = 0 ; $i $len ; $i += 2 )
$html .= ‘&#’ . hexdec ( dechex ( ord ( $str [ $i + 1 ])).
sprintf ( «%02s» , dechex ( ord ( $str [ $i ])))). ‘;’ ;
return( $html );
>
?>
There may be situations when a new version of a web site, all in UTF-8, has to display some old data remaining in the database with ISO-8859-1 accents. The problem is iconv(«ISO-8859-1», «UTF-8», $string) should not be applied if $string is already UTF-8 encoded.
I use this function that does’nt need any extension :
function convert_utf8( $string ) <
if ( strlen(utf8_decode($string)) == strlen($string) ) <
// $string is not UTF-8
return iconv(«ISO-8859-1», «UTF-8», $string);
> else <
// already UTF-8
return $string;
>
>
I have not tested it extensively, hope it may help.
Here is how to convert UCS-2 numbers to UTF-8 numbers in hex:
function ucs2toutf8 ( $str )
<
for ( $i = 0 ; $i strlen ( $str ); $i += 4 )
<
$substring1 = $str [ $i ]. $str [ $i + 1 ];
$substring2 = $str [ $i + 2 ]. $str [ $i + 3 ];
if ( $substring1 == «00» )
<
$byte1 = «» ;
$byte2 = $substring2 ;
>
else
<
$substring = $substring1 . $substring2 ;
$byte1 = dechex ( 192 +( hexdec ( $substring )/ 64 ));
$byte2 = dechex ( 128 +( hexdec ( $substring )% 64 ));
>
$utf8 .= $byte1 . $byte2 ;
>
return $utf8 ;
>
echo strtoupper ( ucs2toutf8 ( «06450631062D0020» ));
?>
Input:
06450631062D
Output:
D985D8B1D8AD
I have used iconv to convert from cp1251 into UTF-8. I spent a day to investigate why a string with Russian capital ‘Р’ (sounds similar to ‘r’) at the end cannot be inserted into a database.
The problem is not in iconv. But ‘Р’ in cp1251 is chr(208) and ‘Р’ in UTF-8 is chr(208).chr(106). chr(106) is one of the space symbol which match ‘\s’ in regex. So, it can be taken by a greedy ‘+’ or ‘*’ operator. In that case, you loose ‘Р’ in your string.
For example, ‘ГР ‘ (Russian, UTF-8). Function preg_match. Regex is ‘(.+?)[\s]*’. Then ‘(.+?)’ matches ‘Г’.chr(208) and ‘[\s]*’ matches chr(106).’ ‘.
Although, it is not a bug of iconv, but it looks like it very much. That’s why I put this comment here.
Didn’t know its a feature or not but its works for me (PHP 5.0.4)
test it to convert from windows-1251 (stored in DB) to UTF-8 (which i use for web pages).
BTW i convert each array i fetch from DB with array_walk_recursive.
In my case, I had to change:
( LC_CTYPE , ‘cs_CZ’ );
?>
to
( LC_CTYPE , ‘cs_CZ.UTF-8’ );
?>
Otherwise it returns question marks.
When I asked my linux for locale (by locale command) it returns «cs_CZ.UTF-8», so there is maybe correlation between it.
iconv (GNU libc) 2.6.1
glibc 2.3.6
I just found out today that the Windows and *NIX versions of PHP use different iconv libraries and are not very consistent with each other.
Here is a repost of my earlier code that now works on more systems. It converts as much as possible and replaces the rest with question marks:
if (! function_exists ( ‘utf8_to_ascii’ )) <
setlocale ( LC_CTYPE , ‘en_AU.utf8’ );
if (@ iconv ( «UTF-8» , «ASCII//IGNORE//TRANSLIT» , ‘é’ ) === false ) <
// PHP is probably using the glibc library (*NIX)
function utf8_to_ascii ( $text ) <
return iconv ( «UTF-8» , «ASCII//TRANSLIT» , $text );
>
>
else <
// PHP is probably using the libiconv library (Windows)
function utf8_to_ascii ( $text ) <
if ( is_string ( $text )) <
// Includes combinations of characters that present as a single glyph
$text = preg_replace_callback ( ‘/\X/u’ , __FUNCTION__ , $text );
>
elseif ( is_array ( $text ) && count ( $text ) == 1 && is_string ( $text [ 0 ])) <
// IGNORE characters that can’t be TRANSLITerated to ASCII
$text = iconv ( «UTF-8» , «ASCII//IGNORE//TRANSLIT» , $text [ 0 ]);
// The documentation says that iconv() returns false on failure but it returns »
if ( $text === » || ! is_string ( $text )) <
$text = ‘?’ ;
>
elseif ( preg_match ( ‘/\w/’ , $text )) < // If the text contains any letters.
$text = preg_replace ( ‘/\W+/’ , » , $text ); // . then remove all non-letters
>
>
else < // $text was not a string
$text = » ;
>
return $text ;
>
>
>
Here is an example how to convert windows-1251 (windows) or cp1251(Linux/Unix) encoded string to UTF-8 encoding.
function cp1251_utf8 ( $sInput )
<
$sOutput = «» ;
for ( $i = 0 ; $i strlen ( $sInput ); $i ++ )
<
$iAscii = ord ( $sInput [ $i ] );
Be aware that iconv in PHP uses system implementations of locales and languages, what works under linux, normally doesn’t in windows.
Also, you may notice that recent versions of linux (debian, ubuntu, centos, etc) the //TRANSLIT option doesn’t work. since most distros doesn’t include the intl packages (example: php5-intl and icuxx (where xx is a number) in debian) by default. And this because the intl package conflicts with another package needed for international DNS resolution.
Problem is that configuration is dependent of the sysadmin of the machine where you’re hosted, so iconv is pretty much useless by default, depending on what configuration is used by your distro or the machine’s admin.
iconv with //IGNORE works as expected: it will skip the character if this one does not exist in the $out_charset encoding.
If a character is missing from the $in_charset encoding (eg byte \x81 from CP1252 encoding), then iconv will return an error, whether with //IGNORE or not.