Установка кодировки символов Java по умолчанию?
Как правильно установить кодировку символов по умолчанию, используемую JVM (1.5.х) программно?
Я читал, что -Dfile.encoding=whatever раньше был способ пойти для старых JVMs. У меня нет такой роскоши по причинам, в которые я не хочу вдаваться.
и свойство устанавливается, но это, похоже, не вызывает окончательный вызов getBytes ниже, чтобы использовать UTF8:
15 ответов
к сожалению, file.encoding свойство должно быть указано при запуске JVM; к моменту ввода основного метода кодировка символов, используемая String.getBytes() и конструкторы по умолчанию InputStreamReader и OutputStreamWriter постоянно кэшируется.
As Эдвард грех указывает, в частном случае, как это, переменная окружения JAVA_TOOL_OPTIONS can используется для указания этого свойства, но обычно это делается так это:
Charset.defaultCharset() будет отражать изменения file.encoding свойство, но большинство кода в основных библиотеках Java, которые должны определить кодировку символов по умолчанию, не используют этот механизм.
когда вы кодируете или декодируете, вы можете запросить file.encoding собственность или Charset.defaultCharset() чтобы найти текущую кодировку по умолчанию и использовать соответствующий метод или перегрузку конструктора, чтобы указать ее.
поскольку командная строка не всегда может быть доступна или изменена, например, во встроенных VMs или просто VMs, запущенных глубоко в сценариях, a JAVA_TOOL_OPTIONS переменная предоставляется так, что агенты могут быть запущены в этих случаях.
установив переменную среды (Windows) JAVA_TOOL_OPTIONS до -Dfile.encoding=UTF8 , (Java) System свойство будет устанавливаться автоматически при каждом запуске JVM. Вы будет знать, что параметр был выбран, потому что следующее сообщение будет опубликовано на System.err :
Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF8
У меня есть хакерский способ, который определенно работает!!
таким образом, вы собираетесь обмануть JVM, который будет думать, что charset не установлен и сделать это, чтобы установить его снова в UTF-8, во время выполнения!
Я думаю, что лучший подход, чем установка набора символов платформы по умолчанию, тем более, что у вас, похоже, есть ограничения на влияние на развертывание приложения, не говоря уже о платформе, — это вызвать гораздо более безопасный String.getBytes(«charsetName») . Таким образом, ваше приложение не зависит от вещей, находящихся вне его контроля.
Я лично считаю, что String.getBytes() должно быть устаревшим, так как это вызвало серьезные проблемы в ряде случаев, которые я видел, когда разработчик не учитывал значение по умолчанию кодировка, возможно, меняется.
Я не могу ответить на ваш первоначальный вопрос, но я хотел бы предложить вам несколько советов-не зависите от кодировки JVM по умолчанию. Всегда лучше явно указать желаемую кодировку (например,» UTF-8″) в вашем коде. Таким образом, вы знаете, что он будет работать даже в разных системах и конфигурациях JVM.
Откуда в Java всплывают проблемы с кодировками и возможная причина падения марсианского зонда
Планета Марс уже не первый год населена роботами. То тут, то там появляются беспилотные электрокары и летающие дроны, а в программах, написанных на Java, с завидной регулярностью всплывают проблемы с кодировками.
Хочу поделиться своими мыслями о том, почему это происходит.
Предположим, у нас есть файл, в котором хранится нужный нам текст. Чтобы поработать с этим текстом в Java нам нужно загнать данные в String. Как это сделать?
Обратите внимание, что для чтения файла недостаточно просто знать его имя. Нужно еще знать, в какой кодировке в нем находятся данные. Двоичное представление символов в памяти Java-машины и в файле на жестком диске практически никогда не совпадает, поэтому нельзя просто взять и скопировать данные из файла в строку. Сначала нужно получить последовательность байт, а уже потом произвести преобразование в последовательность символов. В приведенном примере это делает класс InputStreamReader.
Код получается достаточно громоздким при том, что необходимость в преобразовании из байтов в символы и обратно возникает очень часто. В связи с этим логичным было бы предоставить разработчику вспомомогательные функции и классы, облегчающие работу по перекодировке. Что для этого сделали разработчики Java? Они завели функции, которые не требуют указания кодировки. Например, класс InputStreamReader имеет конструктор с одним параметром типа InputStream.
Стало чуть попроще. Но здесь разработчики Java закопали серьезные грабли. В качестве кодировки для преобразования данных они использовали так называемый «default character encoding».
Default charset устанавливается Java-машиной один раз при старте на основании данных взятых из операционной системы и сохраняется для информационных целей в системном свойстве file.encoding. В связи с этим возникают следующие проблемы.
- Кодировка по умолчанию — это глобальный параметр. Нельзя установить для одних классов или функций одну кодировку, а для других — другую.
- Кодировку по умолчанию нельзя изменить во время выполнения программы.
- Кодировка по умолчанию зависит от окружения, поэтому нельзя заранее знать, какая она будет.
- Поведение методов, зависящих от кодировки по умолчанию, нельзя надежно покрыть тестами, потому что кодировок достаточно много, и множество их значений может расширяться. Может выйти какая-нибудь новая ОС с кодировкой типа UTF-48, и все тесты на ней окажутся бесполезными.
- При возникновении ошибок приходится анализировать больше кода, чтобы узнать, какую именно кодировку использовала та или иная функция.
- Поведение JVM в случае изменения окружения после старта становится непредсказуемо.
Но главное — это то, что от разработчика скрывается важный аспект работы программы, и он может просто не заметить, что использовал функцию, которая в разном окружении будет работать по-разному. Класс FileReader вообще не содержит функций, которые позволяют указать кодировку, хотя сам класс логичен и удобен, поэтому он стимулирует пользователя на создание платформозависимого кода.
Из-за этого происходят удивительные вещи. Например, программа может неправильно открыть файл, который ранее сама же создала.
Или, скажем, есть у нас XML-файл, у которого в заголовке написано encoding=«UTF-8», но в Java-программе этот файл открывается при помощи класса FileReader, и привет. Где-то откроется нормально, а где-то нет.
Особенно ярко проблема file.encoding проявляется в Windows. В ней Java в качестве кодировки по умолчанию использует ANSI-кодировку, которая для России равна Cp1251. В самой Windows говорится, что «этот параметр задает язык для отображения текста в программах, не поддерживающих Юникод». При чем здесь Java, которая изначально задумывалась для полной поддержки Юникода, непонятно, ведь для Windows родная кодировка — UTF-16LE, начиная где-то с Windows 95, за 3 года до выхода 1-й Java.
Так что если вы сохранили при помощи Java-программы файл у себя на компьютере и отправили его вашему коллеге в Европу, то получатель при помощи той же программы может и не суметь открыть его, даже если версия операционной системы у него такая же как и у вас. А когда вы переедете с Windows на Mac или Linux, то вы уже и сами свои файлы можете не прочитать.
А ведь еще есть Windows консоль, которая работает в OEM-кодировке. Все мы наблюдали, как вплоть до Java 1.7 любой вывод русского текста в черном окне при помощи System.out выдавал крокозябры. Это тоже результат использования функций, основанных на default character encoding.
Я у себя проблему кодировок в Java решаю следующим образом:
- Всегда запускаю Java с параметром -Dfile.encoding=UTF-8. Это позволяет убрать зависимость от окружения, делает поведение программ детерминированным и совместимым с большинством операционных систем.
- При тестировании своих программ обязательно делаю тесты с нестандартной (несовместимой с ASCII) кодировкой по умолчанию. Это позволяет отловить библиотеки, которые пользуются классами типа FileReader. При обнаружении таких библиотек стараюсь их не использовать, потому что, во-первых, с кодировками обязательно будут проблемы, а во-вторых, качество кода в таких библиотеках вызывает серьезные сомнения. Обычно я запускаю java с параметром -Dfile.encoding=UTF-32BE, чтобы уж наверняка.
Это не дает стопроцентной гарантии от проблем, потому что есть же еще и лаунчеры, которые запускают Java в отдельном процессе с теми параметрами, которые считают нужными. Например, так делали многие плагины к анту. Сам ант работал с file.encoding=UTF-8, но какой-нибудь генератор кода, вызываемый плагином, работал с кодировкой по умолчанию, и получалась обычная каша из разных кодировок.
По идее, со временем код должен становиться более качественным, программы более надежными, форматы более стандартизованными. Однако этого не происходит. Вместо этого наблюдается всплеск ошибок с кодировками в Java-программах. Видимо, это связано с тем, что в мир Java иммигрировали люди, не привыкшие решать проблему кодировок. Скажем, в C# по умолчанию применяется кодировка UTF-8, поэтому разработчик, переехавший с C#, вполне разумно считает, что InputStreamReader по умолчанию использует эту же кодировку, и не вдается в детали его реализации.
Недавно наткнулся на подобную ошибку в maven-scr-plugin.
Но настоящее удивление пришлось испытать при переезде на восьмерку. Тесты показали, что проблема с кодировкой затесалась в JDK.
На девятке не воспроизводится, видимо, там уже починили.
Поискав по базе ошибок, я нашел еще одну недавно закрытую ошибку, связанную с теми же самыми функциями. И что характерно, их даже исправляют не совсем правильно. Коллеги забывают, что для стандартных кодировок, начиная с Java 7, следует использовать константы из класса StandardCharsets. Так что впереди, к сожалению, нас ждет еще масса сюрпризов.
Запустив grep по исходникам JDK, я нашел десятки мест, где используются платформозависимые функции. Все они будут работать некорректно в окружении, где родная кодировка, несовместима с ASCII. Например, класс Currency, хотя казалось бы, уж этот-то класс должен учитывать все аспекты локализации.
Когда некоторые функции начинают создавать проблемы, и для них существует адекватная альтернатива, давно известно, что нужно делать. Нужно отметить эти функции как устаревшие и указать, на что их следует заменить. Это хорошо зарекомендовавший себя механизм deprecation, который даже планируют развивать.
Я считаю, что функции, зависящие от кодировки по умолчанию, надо обозначить устаревшими, тем более, что их не так уж и много:
| Функция | На что заменить |
|---|---|
| Charset.defaultCharset() | удалить |
| FileReader.FileReader(String) | FileReader.FileReader(String, Charset) |
| FileReader.FileReader(File) | FileReader.FileReader(File, Charset) |
| FileReader.FileReader(FileDescriptor) | FileReader.FileReader(FileDescriptor, Charset) |
| InputStreamReader.InputStreamReader (InputStream) | InputStreamReader.InputStreamReader (InputStream, Charset) |
| FileWriter.FileWriter(String) | FileWriter.FileWriter(String, Charset) |
| FileWriter.FileWriter(String, boolean) | FileWriter.FileWriter(String, boolean, Charset) |
| FileWriter.FileWriter(File) | FileWriter.FileWriter(File, Charset) |
| FileWriter.FileWriter(File, boolean) | FileWriter.FileWriter(File, boolean, Charset) |
| FileWriter.FileWriter(FileDescriptor) | FileWriter.FileWriter(FileDescriptor, Charset) |
| OutputStreamWriter.OutputStreamWriter (OutputStream) | OutputStreamWriter.OutputStreamWriter (OutputStream, Charset) |
| String.String(byte[]) | String.String(byte[], Charset) |
| String.String(byte[], int, int) | String.String(byte[], int, int, Charset) |
| String.getBytes() | String.getBytes(Charset) |
Да, а что там с космическим аппаратом на Марсе?
Часть программного обеспечения для марсианского зонда Скиапарелли написали на Java, на актуальной в то время версии 1.7. Запустили изделие весной, и путь к месту назначения составил полгода. Пока он летел, в Европейском космическом агентстве обновили JDK.
Ну а что? Разработка софта для нынешней миссии завершена, надо делать ПО уже для следующей, а мы все еще на семерке сидим. НАСА и Роскосмос уже давно на восьмерку перешли, а там лямбды, стримы, интерфейсные методы по умолчанию, новый сборщик мусора, и вообще.
Обновились и перед посадкой отправили на космический аппарат управляющую команду не в той кодировке, в которой он ожидал.
Кодировки UTF-8 и Windows 1251 — просто о сложном

Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
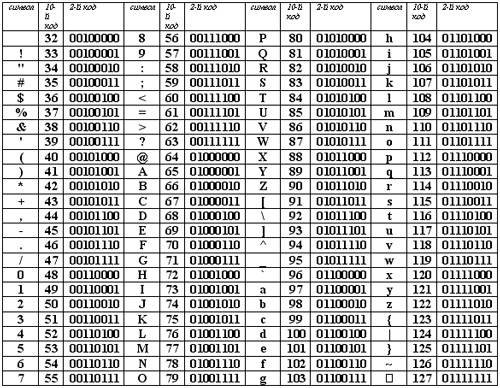
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
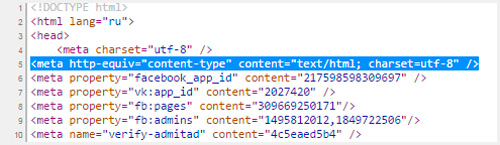
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
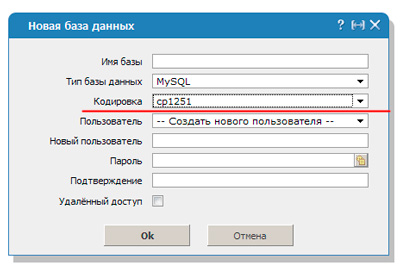
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251»
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.