Мониторим ядра CPU в Zabbix и создаем произвольные счетчики в Low-level discovery
Не так давно тут проходила статья про LLD. Мне она показалась скучной т.к. описывает примерно то же, что есть и в документации. Я решил пойти дальше и с помощью LLD мониторить те параметры, которые раньше нельзя было мониторить автоматически, либо это было достаточно сложно. Разберем работу LLD на примере логических процессоров в Windows: 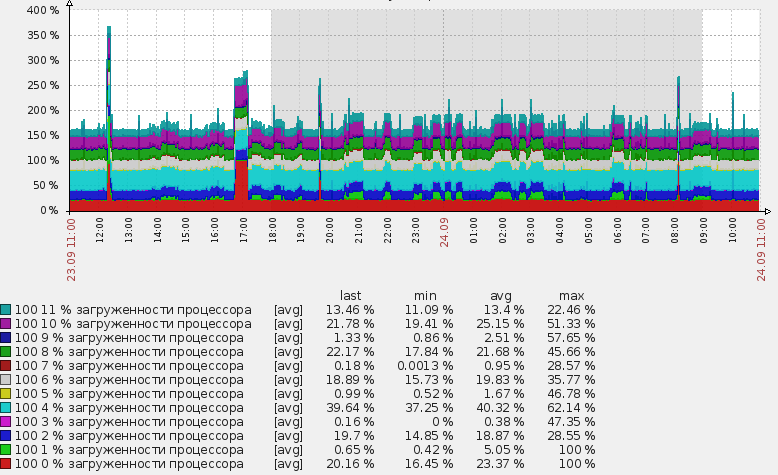
Изначально интересовал расширенный монтиринг помимо ядрер CPU и нагрузка на физические диски. До того как обнаружение было введено, эти задачи частично решались ручным добавлением. Я добавлял условные диски в файл конфигурации zabbix_agent и вообще по-разному извращался. В результате это было очень неудобно, добавлялось много неприятной ручной работы и вообще неправильно в общем как-то было 🙂
В итоге получается схема, которая автоматически определяет ядра в системе, а также физические диски, установленные в системе и добавляет необходимые элементы сбора данных. Для того, чтобы узнать как это реализовать у себя, добро пожаловать под кат. Я попытаюсь более-менее подробно расписать работу на примере CPU и то как сделать тоже самое, но для физических дисков.
Тип отправляемых данных
Для начала стоит отослать к документации, где расписывается что такое LLD и с чем его едят. Помимо стандартных шаблонов нас будет интересовать 4-ый раздел с описание JSON формата обнаружения. То есть мы будем создавать свой собственный метод обнаружения. По сути все сводится к вызову скрипта, который формирует в нужном формате нужные данные.
Создаем скрипт.
Для скрипта я выбрал powershell. Его я знаю немного лучше других скриптовых языков, да и учитывая, что все будет крутиться во круг WMI, сделать его можно было бы и на VBS.
Итак, скрипт.
Задача скрипта состоит в том, чтобы определить число логических процессоров с помощью WMI и вывести в консоль эти данные в формате JSON. Передавать мы будем переменную с именем , а также ее значения. Формат вывода будет примерно таким, в зависимости от количества логических процессоров:
Скрипт формирования данных
Сам скрипт выглядит так:
Сейчас мы получаем, что при запуске скрипта он узнает сколько ядер и формирует пакет для отправки.
Что же мы делаем дальше? Нужно создать Discovery rule.
Добавялем низкоуровневое обнаружение в настройках zabbix сервера
Для этого заходим в нужный шаблон, который добавлен к интересующим нас хостам, в раздел Discovery и нажимаем кнопку Create discovery rule. 
Тут мы видим непонятное значение поля key: PSScript[proc.ps1]. Это UserParameter. Этот пункт создан для удобства, теперь в каждом новом объекте мы можем просто вписывать параметр в виде имени PS скрипта и он будет искать его в заранее оговоренном месте. Сам параметр прописывается в файле конфигурации клиента (обычно называется zabbix_agentd.conf) и выглядит так:
Мы создали новое правило обнаружения с пользовательским сбором данных. Запрос на изменение информации задан как 1 час. Пожалуй, для таких статических данных, как количество процессоров, это слишком часто :), но каждый волен поставить свое значение. Для первоначального сбора данных и отладки лучше это значение уменьшить до совсем небольших значений, чтобы не ждать часами выполнение скрипта.
Настройка прототипов данных
Хорошо. Данные о количестве процессоров мы начали собирать. Но в результате нам нужны не эти данные, а новый item в мониторинге. Именно item может собирать данные, а не наш скрипт, наш скрипт служит только для обнаружения самих элементов для сбора данных.
А для того что бы создать новый элемент сбора данных, полученный на основании LLD, в том же разделе Discovery мы создаем новый прототип. Для этого заходим в item prototypes и нажимаем create item prototype. Я создал вот такой элемент сбора: 
Для сбора данных используется стандартный счетчик производительности. В zabbix для сбора этих данных есть ключ perf_counter. Вместо номера логического ядра мы вставляем полученное значение в виде переменной из раздела Discovery.
Теперь все готово. Или почти все…
С этого момента, когда скрипт discovery обнаружит логические процессоры, для этого хоста будут созданы элементы сбора данных созданных точно для этого количества процессоров.
И теперь если мы зайдем в items для хоста, низкоуровневое обнаружение для которого уже отработало, то мы увидим, что появились новые элементы: 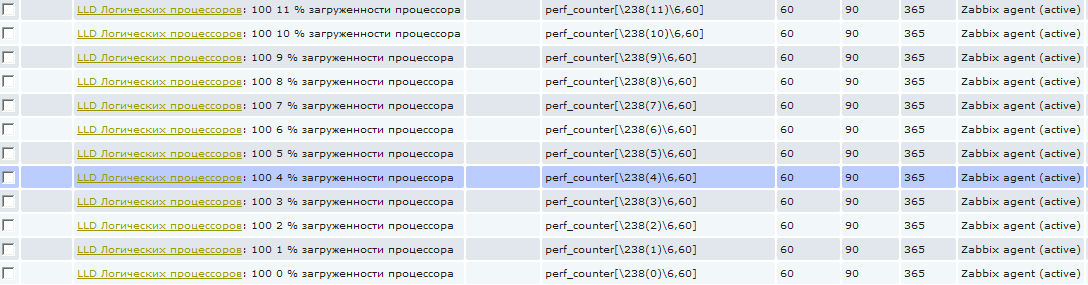
Эти элементы нельзя удалить стандартным способом, т.к. они созданы автоматически, они выделены особенным префиксом с названием правила низкоуровневого обнаружения. На скриншоте кажется, что написана какая-то фигня в имени :), на самом деле все просто, я использую трехзначный код в каждом имени для сортировки. То есть 100 это только лишь сортировочный номер. Следующая цифра от 0 до 11 это номер логического процессора. А дальше уже «% загруженности процессора». А то сначала может показаться, что это 0% загруженности процессора и я пытаюсь это значение собрать 🙂
Единственный недостаток всего этого метода в том, что график, такой как в заголовке этого поста, нельзя создать с помощью механизма низкоуровневого обнаружения. То есть мы можем, конечно, создать не только item, но и graph объект для каждого логического процессора, но создать один суммарный график автоматически со всеми обнаруженными логическими процессорами не получится. По крайней мере я не видел как это можно было бы сделать, на форуме zabbix мне также не смогли подсказать. Это, конечно, не особенно серьезный недостаток, но если у вас 200 хостов, это может стать проблемой :). Ведь график для каждого хоста нужно будет создавать вручную.
Мониторим производительность каждого физического диска в системе
В вышеприведённом способе лучше разобраться и тогда это открывает достаточно широкие возможности для мониторинга объектов в системе, количество которых либо отличается от хоста к хосту либо их количество во все изменяется во время работы.
Например, часто случается, что нужно определить, не происходил ли недостаток в ресурсах физического диска, установленного в сервере. Чаще всего эти данные сложно уловить в реалтайме и хочется иметь их собранными постфактум. Для этого я ввел аналогичное обнаружение и для физических дисков для сбора обширной статистики по ним. И, в отличии от процессоров, элементов сбора данных я создал их с избытком. 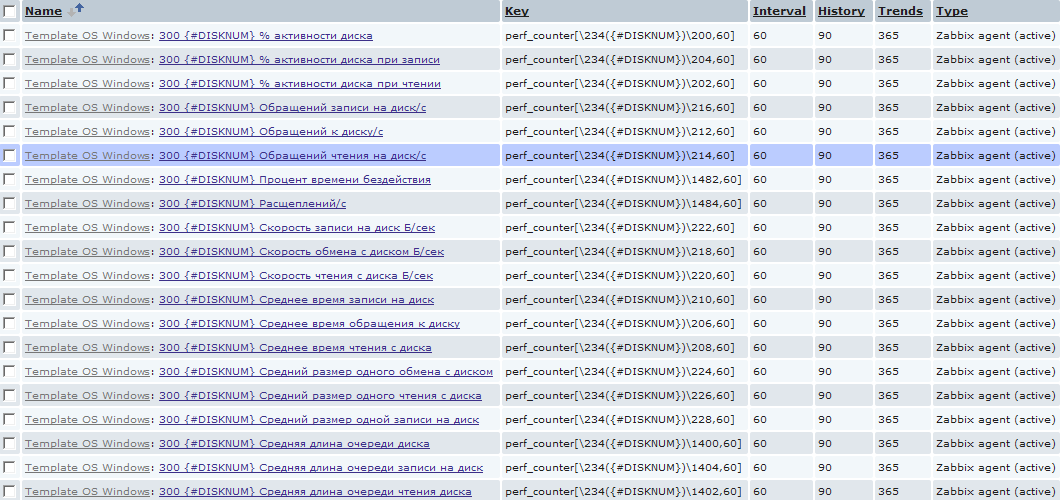
Тут, конечно, надо быть внимательным и если mysql у вас стоит на каком-нибудь стареньком забитом компе, то подобное количество достаточно быстро унесет вашу базу данных в небеса. Т.к. в приведенном примере для каждого хоста создается для каждого физического диска 20 новых элементов, которые будут создавать одного новое значение в минуту. В масштабе пары десятков серверов с кучами разных дисков это выливается в более-менее весомое количество данных. Но тут каждый волен выбирать свой путь самурая 🙂
Скрипт для LLD физических дисков выглядит так:
Добавляем новое правило обнаружения по аналогии с CPU. Точно также мы создаем нужные элементы в discovery.
Вообще, конечно, этот механизм дает довольно большие возможности по определению различных элементов для мониторинга. Таким же способом можно, например, добавить мониторинг сетевых интерфейсов, процессов в системе, служб и любых других элементов, имя которых и количество заранее неизвестно.
Надеюсь эта статья кому-нибудь поможет разобраться с LLD. С удовольствием отвечу на возникшие вопросы.
Zabbix 2.2: Мониторинг температуры процессора Windows машины

При первом знакомстве с zabbix, меня переполняли эмоции и фантазии о мониторинге всего на свете. Первой была идея предотвращения физических неисправностей путем отслеживания основных показателей железа, например температуру или напряжение, поскольку мне видится весьма логичным и экономически выгодным, поменять термопасту или начать подбирать замену уставшей технике до того как пользователь сообщит о её преждевременной кончине или страшных тормозах.
Система мониторинга Zabbix действительно очень мощная и гибкая, но, к сожалению, далеко не все аспекты для отслеживания доступны из стандартных коробочных шаблонов. Таким образом, моя фантазия с треском разбилась об стену отсутствия штатных инструментов мониторинга температур в Windows.
Процесс поиска в интернете поставил меня перед фактом, что вытащить температуры железа без сторонних средств нельзя. При поиске этих самых средств, я столкнулся с популярной утилитой SpeedFan, которая умеет собирать данные о температуре устройств, скорости вентиляторов, напряжений. Но получить от неё готовые к обработке данные без установки еще одной утилиты нет возможности. Плюс ко всему они не open source и требует активации компонента SNMP протокола. Вывод: попробовать на windows сервере без IMPI можно, но как вариант массового распространения в сети – не годен. Дальнейший поиск навел на программы hwmonitor и aida64 — монстры, крупногабаритные и платные.
OpenHardwareMonitor
Уже почти отчаявшись, зацепился за короткое сообщение на англоязычном форуме zabbix. Рекомендовали небольшую open source утилиту OpenHardwareMonitor — она имеет графический интерфейс и умеет считывать температуру устройств с датчиков. И самое главное её автор, по просьбе трудящихся написал консольную версию(последняя версия 28.10.2012), выводящую информацию в готовой для обработки форме.
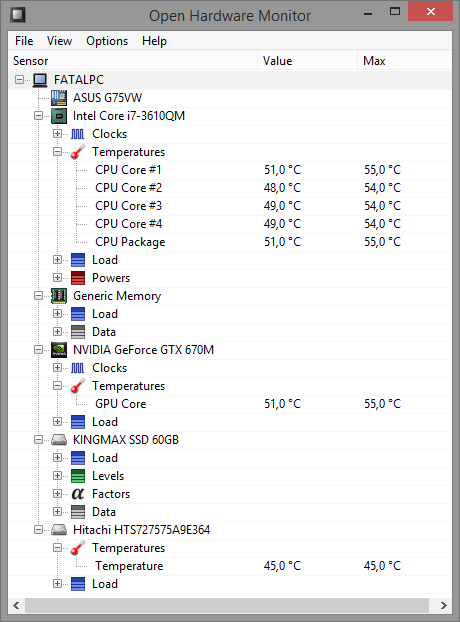
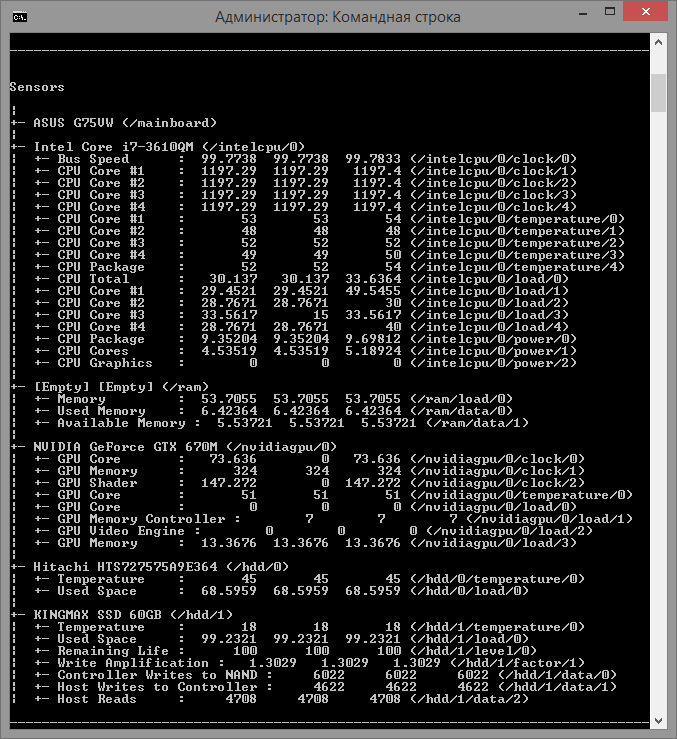
Консольная версия состоит из двух файлов, exe исполняемого файла и dll библиотеки.
- OpenHardwareMonitorReport.exe
- OpenHardwareMonitorLib.dll
Где брать данные мы поняли, теперь нужно наладить поставки значений показателей Zabbix серверу.
Настройка сервера
Для начала на сервер для узла сети добавим новый элемент данных:
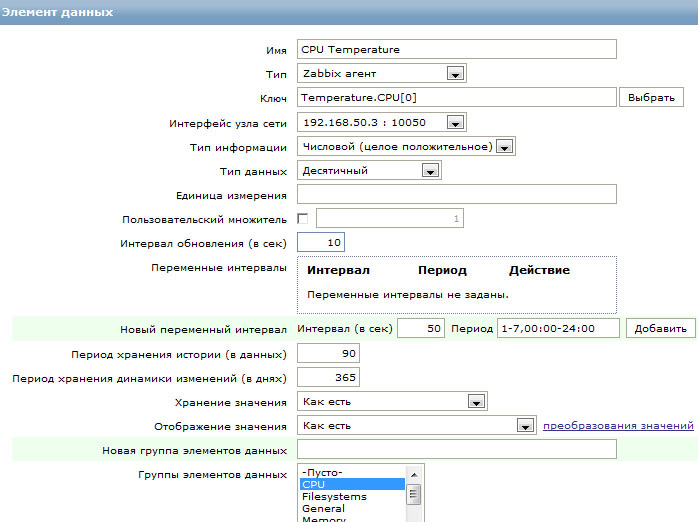
Назовем его: CPU Temperature. (Температура процессора)
Тип: Zabbix агент
Ключ: Temperature.CPU[0]. (Название не принципиально, главное чтобы с конфигом агента совпадал).
Интерфейс узла сети: ip\dns. (Узел, который будем мониторить).
Тип информации: Числовой (целое положительное)
Тип данных: Десятичный
Интервал обновлений (в сек): 3600. (На скриншоте стоит 10 сек, для временной проверки).
На сервере закончили, переходим к конфигурации клиента.
Настройка клиента
Нестандартные данные мы будем отправлять через Zabbix agent в конфиге(zabbix_agentd.conf) которого предусмотрены так называемые пользовательские параметры – UserParameters вида:
Команда, через которую мы получим значение, обрабатывается на стороне клиента. Zabbix сервер будет получать ключ с присвоенным ему значением. В статье имеется в виду, что агент у вас уже установлен в виде службы и дружит с сервером.
В конец конфиг файла агента добавляем:
CPUTemperature.bat — написанный мной batch файл который вытаскивает из OpenHardwareMonitor, среднюю температуру по процессору. В программе эта строка называется CPU Package.
В C:\OpenHardwareMonitor лежат 3 файла:
- OpenHardwareMonitorReport.exe
- OpenHardwareMonitorLib.dll
- CPUTemperature.bat
Инвалид на костылях.
Взываю к habra-сообществу о помощи в преобразовании этого ужаса в нормальный программный код без костылей из текстовых файлов.
Тем не менее, со своей задачей скрипт справляется.
Обновлено: Новый код от уважаемого cawaleb
Для процессоров intel так же справедлив вариант с find вместо findstr и регулярным выражением:
Скрипт возвращает значение в виде десятичного числа.
После этого изменения конфиг файла и размещения всех файлов и скриптов, перезагружаем службу zabbix agent.
Начинаем получать значения на сервер:
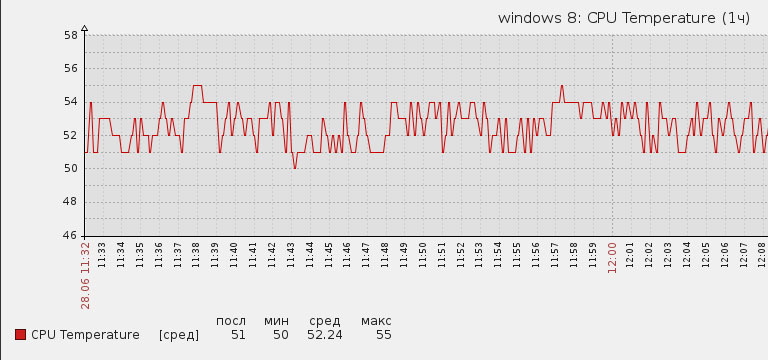
Заключение
Решена задача по извлечения температуры CPU. По той же схеме можно получить температуру GPU. Но по-прежнему остро стоят вопросы определения скорости работы вентиляторов, напряжения на бп, а так же вопрос есть ли способ проверки состояния северного и южного мостов.
Ad Widget
![]()
Windows service CPU utilization
Hello guys, I am new in zabbix.
I just wanted to capture how much my cpu is utilize by server and process or service which is running on that server.
for particular process try like this
![]()
Hello guys, I am new in zabbix.
I just wanted to capture how much my cpu is utilize by server and process or service which is running on that server.
for particular process try like this
To monitor CPU utilization in Windows, use performance counter: \Processor(_Total)\% Processor Time. What is wrong with this counter?
If you want to capture load (which is different) you can use these items:
- system.cpu.load[percpu,avg1]
- system.cpu.load[percpu,avg5]
- system.cpu.load[percpu,avg15]
Individual process in Windows is tricky because the value is based out of total number of cores. If a box have 4 cores, the value collected would be out of 400%.
Comment
![]()
To monitor CPU utilization in Windows, use performance counter: \Processor(_Total)\% Processor Time. What is wrong with this counter?
If you want to capture load (which is different) you can use these items:
- system.cpu.load[percpu,avg1]
- system.cpu.load[percpu,avg5]
- system.cpu.load[percpu,avg15]
Individual process in Windows is tricky because the value is based out of total number of cores. If a box have 4 cores, the value collected would be out of 400%.
this above one giving me proper cpu utilization.
I understand what u said about Individual process. that why