Ассемблер в Linux для программистов C
- Источник — «Ассемблер в Linux для программистов C»
- Последнее изменение этой страницы: 22:45, 1 февраля 2009.
- Текст публикуется с разрешения автора, распространяется по GNU Free Documentation License .
| начиная со старшего байта: | 0x01 0x02 0x03 0x04 | — big-endian |
| начиная с младшего байта: | 0x04 0x03 0x02 0x01 | — little-endian |
Вот эта байтовая последовательность располагается в оперативной памяти, адрес всего слова в памяти — адрес первого байта последовательности.
Если первым располагается младший байт (запись начинается с ) — такой порядок байт называется little-endian, или . Именно он используется в процессорах x86.
Если первым располагается старший байт (запись начинается с ) — такой порядок байт называется big-endian.
У порядка little-endian есть одно важное достоинство. Посмотрите на запись числа 0x00000033 :
Если прочесть его как двухбайтовое значение, получим 0x0033 . Если прочесть как однобайтовое, получим 0x33 . При записи этот трюк тоже работает. Конечно же, мы не можем прочитать число 0x11223344 как байт, потому что получим 0x44 , что неверно. Поэтому считываемое число должно помещаться в целевой диапазон значений.
См. также
Hello, world!
При изучении нового языка принято писать самой первой программу, выводящую на экран строку Hello, world! . Сейчас мы не ставим перед собой задачу понять всё написанное. Главное — посмотреть, как оформляются программы на ассемблере, и научиться их компилировать.
Вспомним, как вы писали Hello, world! на Си. Скорее всего, приблизительно так:
Вот только printf(3) — функция стандартной библиотеки Си, а не операционной системы. — спросите вы. Да, в общем, всё нормально, но, программируя на ассемблере, вы, наверно, хотите взаимодействовать непосредственно с операционной системой, а не с библиотекой Си. Это, конечно же, не значит, что из ассемблера нельзя вызывать функции библиотеки Си. Просто мы пойдём более низкоуровневым путём.
Как вы уже, наверно, знаете, стандартный вывод ( stdout ), в который выводит данные printf(3) , является обычным файловым дескриптором, заранее открываемый операционной системой. Номер этого дескриптора — 1. Теперь нам на помощь придёт системный вызов write(2) .
А вот и сама программа:
Почему sizeof(str) — 1 ? Потому, что строка в Си заканчивается нулевым байтом, а его нам печатать не нужно.
Теперь скопируйте следующий текст в файл hello.s . Файлы исходного кода на ассемблере имеют расширение .s .
Напомним, сейчас наша задача — скомпилировать первую программу. Подробное объяснение этого кода будет потом.
Если компиляция проходит успешно, GCC ничего не выводит на экран. Теперь запускаем нашу программу и убеждаемся, что она корректно завершилась с кодом возврата 0.
Теперь посоветуем прочитать главу про отладчик GDB. Он вам понадобится для исследования работы ваших программ. Возможно, сейчас вы не всё поймёте, но эта глава специально расположена в конце, так как задумана больше как справочная, нежели обучающая. Для того, чтобы научиться работать с отладчиком, с ним нужно просто работать.
Синтаксис ассемблера
Команды
Команды ассемблера — это те инструкции, которые будет исполнять процессор. По сути, это самый низкий уровень программирования процессора. Каждая команда состоит из операции (что делать?) и операндов (аргументов). Операции мы будем рассматривать отдельно. А операнды у всех операций задаются в одном и том же формате. Операндов может быть от 0 (то есть нет вообще) до 3. В роли операнда могут выступать:
- Конкретное значение, известное на этапе компиляции, — например, числовая константа или символ. Записываются при помощи знака $ , например: $0xf1 , $10 , $hello_str . Эти операнды называются непосредственными.
- Регистр. Перед именем регистра ставится знак % , например: %eax , %bx , %cl .
- Указатель на ячейку в памяти (как он формируется и какой имеет синтаксис записи — далее в этом разделе).
- Неявный операнд. Эти операнды не записываются непосредственно в исходном коде, а подразумеваются. Нет, конечно, компьютер не читает ваши мысли. Просто некоторые команды всегда обращаются к определённым регистрам без явного указания, так как это входит в логику их работы. Такое поведение всегда описывается в документации.
Почти у каждой команды можно определить операнд-источник (из него команда читает данные) и операнд-назначение (в него команда записывает результат). Общий синтаксис команды ассемблера такой:
Для того, чтобы привести пример команды, я, немного забегая наперед, расскажу об одной операции. Команда mov источник, назначение производит копирование источника в назначение. Возьмем строку из hello.s :
Как видим, источник — это непосредственное значение 4, а назначение — регистр %eax . Суффикс l в имени команды указывает на то, что ей следует работать с операндами длиной в 4 байта. Все суффиксы:
- b (от англ. byte) — 1 байт,
- w (от англ. word) — 2 байта,
- l (от англ. long) — 4 байта,
- q (от англ. quad) — 8 байт.
Таким образом, чтобы записать $42 в регистр %al (а он имеет размер 1 байт):
Важной особенностью всех команд является то, что они не могут работать с двумя операндами, находящимися в памяти. Хотя бы один из них следует сначала загрузить в регистр, а затем выполнять необходимую операцию.
Как формируется указатель на ячейку памяти? Синтаксис:
Вычисленный адрес будет равен база + индекс ? множитель + смещение. Множитель может принимать значения 1, 2, 4 или 8. Например:
- (%ecx) адрес операнда находится в регистре %ecx . Этим способом удобно адресовать отдельные элементы в памяти, например, указатель на строку или указатель на int ;
- 4(%ecx) адрес операнда равен %ecx + 4. Удобно адресовать отдельные поля структур. Например, в %ecx адрес некоторой структуры, второй элемент которой находится 4 байта от её начала (говорят );
- -4(%ecx) адрес операнда равен %ecx ? 4;
- foo(,%ecx,4) адрес операнда равен foo + %ecx ? 4, где foo — некоторый адрес. Удобно обращаться к элементам массива. Если foo — указатель на массив, элементы которого имеют размер 4 байта, то мы можем заносить в %ecx номер элемента и таким образом обращаться к самому элементу.
Ещё один важный нюанс: команды нужно помещать в секцию кода. Для этого перед командами нужно указать директиву .text . Вот так:
Данные
Существуют директивы ассемблера, которые размещают в памяти данные, определенные программистом. Аргументы этих директив — список выражений, разделенных запятыми.
- .byte — размещает каждое выражение как 1 байт;
- .short — 2 байта;
- .long — 4 байта;
- .quad — 8 байт.
Также существуют директивы для размещения в памяти строковых литералов:
- .ascii «STR» размещает строку STR . Нулевых байтов не добавляет.
- .string «STR» размещает строку STR , после которой следует нулевой байт (как в языке Си).
- У директивы .string есть синоним .asciiz (z от англ. zero — ноль, указывает на добавление нулевого байта).
Строка-аргумент этих директив может содержать стандартные escape-последовательности, которые вы использовали в Си, например, \n , \r , \t , \\ , \» и так далее.
Данные нужно помещать в секцию данных. Для этого перед данными нужно поместить директиву .data . Вот так:
Если некоторые данные не предполагается изменять в ходе выполнения программы, их можно поместить в специальную секцию данных только для чтения при помощи директивы .section .rodata :
Приведём небольшую таблицу, в которой сопоставляются типы данных в Си на IA-32 и в ассемблере. Нужно заметить, что размер этих типов в языке Си на других архитектурах (или даже компиляторах) может отличаться.
| Тип данных в Си | Размер (sizeof), байт | Выравнивание, байт | Название |
|---|---|---|---|
| char signed char | 1 | 1 | signed byte (байт со знаком) |
| unsigned char | 1 | 1 | unsigned byte (байт без знака) |
| short signed short | 2 | 2 | signed halfword (полуслово со знаком) |
| unsigned short | 2 | 2 | unsigned halfword (полуслово без знака) |
| int signed int long signed long enum | 4 | 4 | signed word (слово со знаком) |
| unsigned int unsigned long | 4 | 4 | unsigned word (слово без знака) |
Отдельных объяснений требует колонка . Выравнивание задано у каждого фундаментального типа данных (типа данных, которым процессор может оперировать непосредственно). Например, выравнивание word — 4 байта. Это значит, что данные типа word должны располагаться по адресу, кратному 4 (например, 0x00000100, 0x03284478). Архитектура рекомендует, но не требует выравнивания: доступ к невыровненным данным может быть медленнее, но принципиальной разницы нет и ошибки это не вызовет.
Для соблюдения выравнивания в распоряжении программиста есть директива .p2align .
Директива .p2align выравнивает текущий адрес до заданной границы. Граница выравнивания задаётся как степень числа 2: например, если вы указали .p2align 3 — следующее значение будет выровнено по 8-байтной границе. Для выравнивания размещается необходимое количество байт-заполнителей со значением заполнитель. Если для выравнивания требуется разместить более чем максимум байт-заполнителей, то выравнивание не выполняется.
Второй и третий аргумент являются необязательными.
Метки и прочие символы
Вы, наверно, заметили, что мы не присвоили имён нашим данным. Как же к ним обращаться? Очень просто: нужно поставить метку. Метка — это просто константа, значение которой — адрес.
Сама метка, в отличие от данных, места в памяти программы не занимает. Когда компилятор встречает в исходном коде метку, он запоминает текущий адрес и читает код дальше. В результате компилятор помнит все метки и адреса, на которые они указывают. Программист может ссылаться на метки в своём коде. Существует специальная псевдометка, указывающая на текущий адрес. Это метка . (точка).
Значение метки как константы — это всегда адрес. А если вам нужна константа с каким-то другим значением? Тогда мы приходим к более общему понятию . Символ — это просто некоторая константа. Причём он может быть определён в одном файле, а использован в других.
Возьмём hello.s и скомпилируем его так:
Обратите внимание на параметр -c . Мы компилируем исходный код не в исполняемый файл, а лишь только в отдельный объектный файл hello.o . Теперь воспользуемся программой nm(1) :
nm(1) выводит список символов в объектном файле. В первой колонке выводится значение символа, во второй — его тип, в третьей — имя. Посмотрим на символ hello_str_length . Это длина строки Hello, world!\n . Значение символа чётко определено и равно 0xe , об этом говорит тип a — absolute value. А вот символ hello_str имеет тип d — значит, он находится в секции данных (data). Символ main находится в секции кода (text section, тип T ). А почему a представлено строчной буквой, а T — прописной? Если тип символа обозначен строчной буквой, значит это локальный символ, который видно только в пределах данного файла. Заглавная буква говорит о том, что символ глобальный и доступен другим модулям. Символ main мы сделали глобальным при помощи директивы .globl main .
Для создания нового символа используется директива .set . Синтаксис:
Например, определим символ foo = 42:
Ещё пример из hello.s :
Сначала определяется символ hello_str , который содержит адрес строки. После этого мы определяем символ hello_str_length , который, судя по названию, содержит длину строки. Директива .set позволяет в качестве значения символа использовать арифметические выражения. Мы из значения текущего адреса (метка ) вычитаем адрес начала строки — получаем длину строки в байтах. Потом мы вычитаем ещё единицу, потому что директива .string добавляет в конце строки нулевой байт (а на экран мы его выводить не хотим).
Неинициализированные данные
Часто требуется просто зарезервировать место в памяти для данных, без инициализации какими-то значениями. Например, у вас есть переменная, значение которой определяется параметрами командной строки. Действительно, вы вряд ли сможете дать ей какое-то осмысленное начальное значение, разве что 0. Такие данные называются неинциализированными, и для них выделена специальная секция под названием .bss . В скомпилированной программе эта секция места не занимает. При загрузке программы в память секция неинициализированых данных будет заполнена нулевыми байтами.
Хорошо, но известные нам директивы размещения данных требуют указания инициализирующего значения. Поэтому для неинициализированных данных используются специальные директивы:
Директива .space резервирует количество_байт байт.
Также эту директиву можно использовать для размещения инициализированных данных, для этого существует параметр заполнитель — этим значением будет инициализирована память.
Методы адресации
Пространство памяти предназначено для хранения кодов команд и данных, для доступа к которым имеется богатый выбор методов адресации (около 24). Операнды могут находиться во внутренних регистрах процессора (наиболее удобный и быстрый вариант). Они могут располагаться в системной памяти (самый распространенный вариант). Наконец, они могут находиться в устройствах ввода/вывода (наиболее редкий случай). Определение места положения операндов производится кодом команды. Причем существуют разные методы, с помощью которых код команды может определить, откуда брать входной операнд и куда помещать выходной операнд. Эти методы называются методами адресации. Эффективность выбранных методов адресации во многом определяет эффективность работы всего процессора в целом.
Прямая или абсолютная адресация
Физический адрес операнда содержится в адресной части команды. Формальное обозначение:
где Аi — код, содержащийся в i-м адресном поле команды.
Непосредственная адресация
В команде содержится не адрес операнда, а непосредственно сам операнд.
Непосредственная адресация позволяет повысить скорость выполнения операции, так как в этом случае вся команда, включая операнд, считывается из памяти одновременно и на время выполнения команды хранится в процессоре в специальном регистре команд (РК). Однако при использовании непосредственной адресации появляется зависимость кодов команд от данных, что требует изменения программы при каждом изменении непосредственного операнда.
Косвенная (базовая) адресация
Адресная часть команды указывает адрес ячейки памяти или регистр, в котором содержится адрес операнда:
Применение косвенной адресации операнда из оперативной памяти при хранении его адреса в регистровой памяти существенно сокращает длину поля адреса, одновременно сохраняя возможность использовать для указания физического адреса полную разрядность регистра. Недостаток этого способа — необходимо дополнительное время для чтения адреса операнда. Вместе с тем он существенно повышает гибкость программирования. Изменяя содержимое ячейки памяти или регистра, через которые осуществляется адресация, можно, не меняя команды в программе, обрабатывать операнды, хранящиеся по разным адресам. Косвенная адресация не применяется по отношению к операндам, находящимся в регистровой памяти.
Предоставляемые косвенной адресацией возможности могут быть расширены, если в системе команд ЭВМ предусмотреть определенные арифметические и логические операции над ячейкой памяти или регистром, через которые выполняется адресация, например увеличение или уменьшение их значения.
Автоинкрементная и автодекрементная адресация
Иногда, адресация, при которой после каждого обращения по заданному адресу с использованием механизма косвенной адресация, значение адресной ячейки автоматически увеличивается на длину считываемого операнда, называется автоинкрементной. Адресация с автоматическим уменьшением значения адресной ячейки называется автодекрементной.
Регистровая адресация
Предполагается, что операнд находится во внутреннем регистре процессора.
Относительная адресация
Этот способ используется тогда, когда память логически разбивается на блоки, называемые сегментами. В этом случае адрес ячейки памяти содержит две составляющих: адрес начала сегмента (базовый адрес) и смещение адреса операнда в сегменте. Адрес операнда определяется как сумма базового адреса и смещения относительно этой базы:
Для задания базового адреса и смещения могут применяться ранее рассмотренные способы адресации. Как правило, базовый адрес находится в одном из регистров регистровой памяти, а смещение может быть задано в самой команде или регистре.
Рассмотрим два примера:
- Адресное поле команды состоит из двух частей, в одной указывается номер регистра, хранящего базовое значение адреса (начальный адрес сегмента), а в другом адресном поле задается смещение, определяющее положение ячейки относительно начала сегмента. Именно такой способ представления адреса обычно и называют относительной адресацией.
- Первая часть адресного поля команды также определяет номер базового регистра, а вторая содержит номер регистра, в котором находится смещение. Такой способ адресации чаще всего называют базово-индексным.
Главный недостаток относительной адресации — большое время вычисления физического адреса операнда. Но существенное преимущество этого способа адресации заключается в возможности создания «перемещаемых» программ — программ, которые можно размещать в различных частях памяти без изменения команд программы. То же относится к программам, обрабатывающим по единому алгоритму информацию, расположенную в различных областях ЗУ. В этих случаях достаточно изменить содержимое базового адреса начала команд программы или массива данных, а не модифицировать сами команды. По этой причине относительная адресация облегчает распределение памяти при составлении сложных программ и широко используется при автоматическом распределении памяти в мультипрограммных вычислительных системах.
Команды ассемблера
Команда mov
Команда mov производит копирование источника в назначение. Рассмотрим примеры:
Команда lea
lea — мнемоническое от англ. Load Effective Address. Синтаксис:
Команда lea помещает адрес источника в назначение. Например:
Команды для работы со стеком
Предусмотрено две специальные команды для работы со стеком: push (поместить в стек) и pop (извлечь из стека). Синтаксис:
При описании работы стека мы уже обсуждали принцип работы команд push и pop . Важный нюанс: push и pop работают только с операндами размером 4 или 2 байта. Если вы попробуете скомпилировать что-то вроде
GCC вернёт следующее:
Согласно ABI, в Linux стек выровнен по long . Сама архитектура этого не требует, это только соглашение между программами, но не рассчитывайте, что другие библиотеки подпрограмм или операционная система захотят работать с невыровненным стеком. Что всё это значит? Если вы резервируете место в стеке, количество байт должно быть кратно размеру long , то есть 4. Например, вам нужно всего 2 байта в стеке для short , но вам всё равно придётся резервировать 4 байта, чтобы соблюдать выравнивание.
Интересный вопрос: какое значение помещает в стек вот эта команда
Если ещё раз взглянуть на алгоритм работы команды push , кажется очевидным, что в данном случае она должна поместить уже уменьшенное значение %esp . Однако в документации Intel [2] сказано, что в стек помещается такое значение %esp , каким оно было до выполнения команды — и она действительно работает именно так.
Арифметика
Арифметических команд в нашем распоряжении довольно много. Синтаксис:
- inc : увеличивает операнд на 1.
- dec : уменьшает операнд на 1.
- add : приёмник = приёмник + источник (то есть, увеличивает приёмник на источник).
- sub : приёмник = приёмник — источник (то есть, уменьшает приёмник на источник).
Команда mul имеет только один операнд. Второй сомножитель задаётся неявно. Он находится в регистре %eax , и его размер выбирается в зависимости от суффикса команды ( b , w или l ). Место размещения результата также зависит от суффикса команды. Нужно отметить, что результат умножения двух n -разрядных чисел может уместиться только в 2n -разрядном регистре результата. В следующей таблице описано, в какие регистры попадает результат при той или иной разрядности операндов.
| Команда | Второй сомножитель | Результат |
|---|---|---|
| mulb | %al | 16 бит: %ax |
| mulw | %ax | 32 бита: младшая часть в %ax , старшая в %dx |
| mull | %eax | 64 бита: младшая часть в %eax , старшая в %edx |
Давайте подумаем, каким будет результат выполнения следующего кода на Си:
Большинство сразу скажет, что результат (250 + 14 = 264) больше, чем может поместиться в одном байте. И что же напечатает программа? 8. Давайте рассмотрим, что происходит при сложении в двоичной системе.
Получается, что результат занимает 9 бит, а в переменную может поместиться только 8 бит. Это называется переполнением — перенос из старшего бита результата. В Си переполнение не может быть перехвачено, но в микропроцессоре эта ситуация регистрируется, и её можно обработать. Когда происходит переполнение, устанавливается флаг cf . Команды условного перехода jc и jnc анализируют состояние этого флага. Команды условного перехода будут рассмотрены далее, здесь эта информация приводится для полноты описания команд.
Этот код выдаёт правильную сумму в регистре %ax с учётом переполнения, если оно произошло. Попробуйте поменять числа в строках 2 и 3.
Команда lea для арифметики
Для выполнения некоторых арифметических операций можно использовать команду lea [3] . Она вычисляет адрес своего операнда-источника и помещает этот адрес в операнд-назначение. Ведь она не производит чтение памяти по этому адресу, верно? А значит, всё равно, что она будет вычислять: адрес или какие-то другие числа.
Вспомним, как формируется адрес операнда:
Вычисленный адрес будет равен база + индекс ? множитель + смещение.
Чем это нам удобно? Так мы можем получить команду с двумя операндами-источниками и одним результатом:
Вспомните, что при сложении командой add результат записывается на место одного из слагаемых. Теперь, наверно, стало ясно главное преимущество lea в тех случаях, где её можно применить: она не перезаписывает операнды-источники. Как вы это сможете использовать, зависит только от вашей фантазии: прибавить константу к регистру и записать в другой регистр, сложить два регистра и записать в третий: Также lea можно применять для умножения регистра на 3, 5 и 9, как показано выше.
Команда loop
- уменьшить значение регистра %ecx на 1;
- если %ecx = 0, передать управление следующей за loop команде;
- если %ecx ? 0, передать управление на метку.
Напишем программу для вычисления суммы чисел от 1 до 10 (конечно же, воспользовавшись формулой суммы арифметической прогрессии, можно переписать этот код и без цикла — но ведь это только пример).
На Си это выглядело бы так:
Команды сравнения и условные переходы. Безусловный переход
Команда loop неявно сравнивает регистр %ecx с нулём. Это довольно удобно для организации циклов, но часто циклы бывают намного сложнее, чем те, что можно записать при помощи loop . К тому же нужен эквивалент конструкции if()<> . Вот команды, позволяющие выполнять произвольные сравнения операндов:
Команда cmp выполняет вычитание операнд_1 — операнд_2 и устанавливает флаги. Результат вычитания нигде не запоминается.
Сравнили, установили флаги, — и что дальше? А у нас есть целое семейство jump -команд, которые передают управление другим командам. Эти команды называются командами условного перехода. Каждой из них поставлено в соответствие условие, которое она проверяет. Синтаксис:
Команды jcc не существует, вместо cc нужно подставить мнемоническое обозначение условия.
| Мнемоника | Английское слово | Смысл | Тип операндов |
|---|---|---|---|
| e | equal | равенство | любые |
| n | not | инверсия условия | любые |
| g | greater | больше | со знаком |
| l | less | меньше | со знаком |
| a | above | больше | без знака |
| b | below | меньше | без знака |
Таким образом, je проверяет равенство операндов команды сравнения, jl проверяет условие операнд_1 и так далее. У каждой команды есть противоположная: просто добавляем букву n :
- je — jne : равно — не равно;
- jg — jng : больше — не больше.
Теперь пример использования этих команд:
Сравните с кодом на Си:
Кроме команд условного перехода, область применения которых ясна сразу, также существует команда безусловного перехода. Эта команда чем-то похожа на оператор goto языка Си. Синтаксис:
Эта команда передаёт управление на адрес, не проверяя никаких условий. Заметьте, что адрес может быть задан в виде непосредственного значения (метки), регистра или обращения к памяти.
Произвольные циклы
Все инструкции для написания произвольных циклов мы уже рассмотрели, осталось лишь собрать всё воедино. Лучше сначала посмотрите код программы, а потом объяснение к ней. Прочитайте её код и комментарии и попытайтесь разобраться, что она делает. Если сразу что-то непонятно — не страшно, сразу после исходного кода находится более подробное объяснение.
Программа: поиск наибольшего элемента в массиве
Сначала мы заносим в регистр %eax число 0. После этого мы сравниваем каждый элемент массива с текущим наибольшим значением из %eax , и, если этот элемент больше, он становится текущим наибольшим. После просмотра всего массива в %eax находится наибольший элемент.
Этот код соответствует приблизительно следующему на Си:
Возможно, такой способ обхода массива не очень привычен для вас. В Си принято использовать переменную с номером текущего элемента, а не указатель на него. Никто не запрещает пойти этим же путём и на ассемблере:
Рассматривая код этой программы, вы, наверно, уже поняли, как создавать произвольные циклы с постусловием на ассемблере, наподобие do<> while(); в Си. Ещё раз повторю эту конструкцию, выкинув весь код, не относящийся к циклу:
В Си есть ещё один вид цикла, с проверкой условия перед входом в тело цикла (цикл с предусловием): while()<> . Немного изменив предыдущий код, получаем следующее:
Кто-то скажет: а ещё есть цикл for() ! Но цикл
эквивалентен такой конструкции:
Таким образом, нам достаточно и уже рассмотренных двух видов циклов.
Логическая арифметика
Кроме выполнения обычных арифметических вычислений, можно проводить и логические, то есть битовые.
Команды and , or и xor ведут себя так же, как и операторы языка Си & , | , ^ . Эти команды устанавливают флаги согласно результату.
Команда not инвертирует каждый бит операнда на противоположный, так же как и оператор языка Си
Команда test выполняет побитовое И над операндами, как и команда and , но, в отличие от неё, операнды не изменяет, а только устанавливает флаги. Её также называют командой логического сравнения, потому что с её помощью удобно проверять, установлены ли определённые биты. Например, так:
Команду test можно применять для сравнения значения регистра с нулём:
Intel Optimization Manual рекомендует использовать test вместо cmp для сравнения регистра с нулём [4] .
Ещё следует упомянуть об одном трюке с xor . Как вы знаете, a XOR a = 0. Пользуясь этой особенностью, xor часто применяют для обнуления регистров:
Почему применяют xor вместо mov ? Команда xor короче, а значит, занимает меньше места в процессорном кэше, меньше времени тратится на декодирование, и программа выполняется быстрее. Но эта команда устанавливает флаги. Поэтому, если вам нужно сохранить состояние флагов, применяйте mov [5] .
Иногда для обнуления регистра применяют команду sub . Помните, она тоже устанавливает флаги.
К логическим командам также можно отнести команды сдвигов:
количество_сдвигов может быть задано непосредственным значением или находиться в регистре %cl . Учитываются только младшие 5 бит регистра %cl , так что количество сдвигов может варьироваться в пределах от 0 до 31.
Принцип работы команды shl :
Принцип работы команды shr :
Эти две команды называются командами логического сдвига, потому что они работают с операндом как с массивом бит. Каждый бит попадает в флаг cf , причём с другой стороны операнда бит 0. Таким образом, в флаге cf оказывается самый последний бит. Такое поведение вполне допустимо для работы с беззнаковыми числами, но числа со знаком будут обработаны неверно из-за того, что знаковый бит может быть потерян.
Для работы с числами со знаком существуют команды арифметического сдвига. Команды shl и sal выполняют полностью идентичные действия, так как при сдвиге влево знаковый бит не теряется (расширение знакового бита влево становится новым знаковым битом). Для сдвига вправо применяется команда sar . Она слева знаковый бит исходного значения, таким образом сохраняя знак числа:
Многие программисты Си знают об умножении и делении на степени двойки (2, 4, 8:) при помощи сдвигов. Этот трюк отлично работает и в ассемблере, используйте его для оптимизации.
Кроме сдвигов обычных, существуют циклические сдвиги:
Объясню на примере циклического сдвига влево на три бита: три старших ( ) бита из регистра влево и в него справа. При этом в флаг cf записывается самый последний бит.
Принцип работы команды rol :
Принцип работы команды ror :
Существует ещё один вид сдвигов — циклический сдвиг через флаг cf . Эти команды рассматривают флаг cf как продолжение операнда.
Принцип работы команды rcl :
Принцип работы команды rcr :
Эти сложные циклические сдвиги вам редко понадобятся в реальной работе, но уже сейчас нужно знать, что такие инструкции существуют, чтобы не изобретать велосипед потом. Ведь в языке Си циклический сдвиг производится приблизительно так:
Подпрограммы
Термином будем называть и функции, которые возвращают значение, и функции, не возвращающие значение ( void proc(:) ). Подпрограммы нужны для достижения одной простой цели — избежать дублирования кода. В ассемблере есть две команды для организации работы подпрограмм.
Используется для вызова подпрограммы, код которой находится по адресу метка. Принцип работы:
- Поместить в стек адрес следующей за call команды. Этот адрес называется адресом возврата.
- Передать управление на метку.
Для возврата из подпрограммы используется команда ret .
- Извлечь из стека новое значение регистра %eip (то есть передать управление на команду, расположенную по адресу из стека).
- Если команде передан операнд число, %esp увеличивается на это число. Это необходимо для того, чтобы подпрограмма могла убрать из стека свои параметры.
Существует несколько способов передачи аргументов в подпрограмму.
- При помощи регистров. Перед вызовом подпрограммы вызывающий код помещает необходимые данные в регистры. У этого способа есть явный недостаток: число регистров ограничено, соответственно, ограничено и максимальное число передаваемых параметров. Также, если передать параметры почти во всех регистрах, подпрограмма будет вынуждена сохранять их в стек или память, так как ей может не хватить регистров для собственной работы. Несомненно, у этого способа есть и преимущество: доступ к регистрам очень быстрый.
- При помощи общей области памяти. Это похоже на глобальные переменные в Си. Современные рекомендации написания кода (а часто и стандарты написания кода в больших проектах) запрещают этот метод. Он не поддерживает многопоточное выполнение кода. Он использует глобальные переменные неявным образом — смотря на определение функции типа void func(void) невозможно сказать, какие глобальные переменные она изменяет и где ожидает свои параметры. Вряд ли у этого метода есть преимущества. Не используйте его без крайней необходимости.
- При помощи стека. Это самый популярный способ. Вызывающий код помещает аргументы в стек, а затем вызывает подпрограмму.
Рассмотрим передачу аргументов через стек подробнее. Предположим, нам нужно написать подпрограмму, принимающую три аргумента типа long (4 байта). Код:
С вызовом всё ясно: помещаем аргументы в стек и даём команду call . А вот как в подпрограмме достать параметры из стека? Вспомним про регистр %ebp .
Мы сохраняем значение регистра %ebp , а затем записываем в него указатель на текущую вершину стека. Теперь у нас есть указатель на стек в известном состоянии. Сверху в стек можно помещать сколько угодно данных, но у нас останется доступ к параметрам. Часто эта последовательность команд называется подпрограммы.
Используя адрес из %ebp , мы можем ссылаться на параметры:
Как видите, если идти от вершины стека в сторону аргументов, то мы будем встречать аргументы в обратном порядке по отношению к тому, как их туда поместили. Нужно сделать одно из двух: или помещать аргументы в обратном порядке (чтобы доставать их в прямом порядке), или учитывать обратный порядок аргументов в подпрограмме. В Си принято при вызове помещать аргументы в обратном порядке. Так как операционная система Linux и большинство библиотек для неё написаны именно на Си, я советую использовать способ передачи аргументов и в ваших ассемблерных программах.
Подпрограмме могут понадобится собственные локальные переменные. Их принято держать в стеке. Для того, чтобы зарезервировать для них место, мы просто уменьшим содержимое регистра %esp на размер наших переменных. Предположим, что нам нужно 2 переменные типа long (4 байта), итого 2 ? 4 = 8 байт. Мы уменьшим регистр %esp на 8. Теперь стек выглядит так:
Вы не можете делать никаких предположений о содержимом локальных переменных. Никто их для вас не инициализировал нулем. Можете для себя считать, что там находятся случайные значения.
При возврате из процедуры мы восстанавливаем старое значение %ebp из стека, потому что после возврата вызывающая функция вряд ли будет рада найти в регистре %ebp неизвестно что. Для этого необходимо, чтобы старое значение %ebp было на вершине стека. Если подпрограмма что-то поместила в стек после старого %ebp , она должна это убрать. К счастью, мы не должны считать, сколько байт мы поместили, сколько достали и сколько ещё осталось. Мы можем просто поместить значение регистра %ebp в регистр %esp , и стек станет точно таким же, как и после сохранения старого %ebp в начале подпрограммы. После этого команда ret возвращает управление вызывающему коду. Эта последовательность команд часто называется подпрограммы.
Остаётся одна маленькая проблема: в стеке всё ещё находятся аргументы для подпрограммы. Это можно решить одним из следующих способов:
- использовать команду ret с аргументом;
- использовать необходимое число раз команду pop и выбросить результат;
- увеличить %esp на размер всех помещенных в стек параметров.
В Си используется последний способ. Так как мы поместили в стек 3 значения типа long по 4 байта каждый, мы должны увеличить %esp на 12, что и делает команда addl сразу после call .
Заметьте, что не всегда обязательно выравнивать стек. Если вы вызываете несколько подпрограмм подряд (но не в цикле!), то можно разрешить аргументам в стеке, а потом убрать их всех одной командой. Если ваша подпрограмма не содержит вызовов других подпрограмм в цикле и вы уверены, что оставшиеся аргументы в стеке не вызовут проблем переполнения стека, то аргументы можно не убирать вообще. Всё равно это сделает команда эпилога, которая восстанавливает %esp из %ebp . С другой стороны, если не уверены — лучше уберите аргументы, от одной лишней команды программа медленнее не станет.
Строго говоря, все эти действия с %ebp не требуются. Вы можете использовать %ebp для хранения своих значений, никак не связанных со стеком, но тогда вам придётся обращаться к аргументам и локальным переменным через %esp или другие регистры, в которые вы поместите указатели. Трюк состоит в том, чтобы не изменять %esp после резервирования места для локальных переменных и до конца функции: так вы сможете использовать %esp на манер %ebp , как было показано выше. Не изменять %esp значит, что вы не сможете использовать push и pop (иначе все смещения переменных в стеке относительно %esp ); вам понадобится создать необходимое число локальных переменных для хранения этих временных значений. С одной стороны, этот способ доступа к переменным немного сложнее, так как вы должны заранее просчитать, сколько места в стеке вам понадобится. С другой стороны, у вас появляется еще один свободный регистр %ebp . Так что если вы решите пойти этой дорогой, вы должны заранее продумать, сколько места для локальных переменных вам понадобится, и дальше обращаться к ним через смещения относительно %esp .
И последнее: если вы хотите использовать вашу подпрограмму за пределами данного файла, не забудьте сделать её глобальной с помощью директивы .globl .
Посмотрим на код, который выводил содержимое регистра %eax на экран, вызывая функцию стандартной библиотеки Си printf(3) . Вы его уже видели в предыдущих программах, но там он был приведен без объяснений. Для справки привожу цитату из man :
Обратите внимание на обратный порядок аргументов и очистку стека от аргументов.
До этого момента мы обходились общим термином . Но если подпрограмма — функция, она должна как-то передать возвращаемое значение. Это принято делать при помощи регистра %eax . Перед началом эпилога функция должна поместить в %eax возвращаемое значение.
Программа: печать таблицы умножения
Рассмотрим программу посложнее. Итак, программа для печати таблицы умножения. Размер таблицы умножения вводит пользователь. Нам понадобится вызвать функцию scanf(3) для ввода, printf(3) для вывода и организовать два вложенных цикла для вычислений.
Программа: вычисление факториала
Теперь напишем рекурсивную функцию для вычисления факториала. Она основана на следующей формуле: 0! = 1 
Любой программист знает, что если существует очевидное итеративное (реализуемое при помощи циклов) решение задачи, то именно ему следует отдавать предпочтение перед рекурсивным. Итеративный алгоритм нахождения факториала даже проще, чем рекурсивный; он следует из определения факториала: 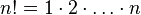
Говоря проще, нужно перемножить все числа от 1 до n .
Функция — на то и функция, что её можно заменить, при этом не изменяя вызывающий код. Для запуска следующего кода просто замените функцию из предыдущей программы вот этой новой версией:
Что я сделал? Сначала я переписал рекурсию в виде цикла. Потом я увидел, что мне больше не нужен кадр стека, так как я не вызываю других функций и ничего не помещаю в стек. Поэтому я убрал пролог и эпилог, при этом регистр %ebp я не использую вообще. Если бы я его использовал, сначала я должен был бы сохранить его значение, а перед возвратом восстановить.
В результате я так увлекся, что решил написать 64-битную версию этой функции. Она возвращает результат в паре %eax:%edx и может вычислить 20! = 2432902008176640000 .
Нам нужно умножить 64-битное число на 32-битное. Мы будем это делать как при умножении :
Но произведение %esi ? %ecx не поместится в 32 бита, останутся ещё старшие 32 бита. Их мы должны прибавить к старшим 32-м битам результата. Приблизительно так вы это делаете на бумаге в десятичной системе:
Задание: напишите программу-считалочку. Есть числа от 0 до m , которые располагаются по кругу. Счёт начинается с элемента 0. Каждый n -й элемент удаляют. Счёт продолжается с элемента, следующего за удалённым. Напишите программу, выводящую список вычеркнутых элементов. Подсказка: используйте malloc(3) для получения m + 1 байт памяти и занесите в каждый байт число 1 при помощи memset(3) . Значение 1 означает, что элемент существует, значением 0 отмечайте удалённые элементы. При счете пропускайте удалённые элементы.
Системные вызовы
Программа, которая не взаимодействует с внешним миром, вряд ли может сделать что-то полезное. Вывести сообщение на экран, почитать данные из файла, установить сетевое соединение — это всё примеры действий, которые программа не может совершить без помощи операционной системы. В Linux пользовательский интерфейс ядра организован через системные вызовы. Системный вызов можно рассматривать как функцию, которую для вас выполняет операционная система.
Теперь наша задача состоит в том, чтобы разобраться, как происходит системный вызов. Каждый системный вызов имеет свой номер. Все они перечислены в файле /usr/include/asm-i386/unistd.h .
Системные вызовы считывают свои параметры из регисторв. Номер системного вызова нужно поместить в регистр %eax . Параметры помещаются в остальные регистры в таком порядке:
- первый — в %ebx ;
- второй — в %ecx ;
- третий — в %edx ;
- четвертый — в %esi ;
- пятый — в %edi ;
- шестой — в %ebp .
Таким образом, используя все регистры общего назначения, можно передать максимум 6 параметров. Системный вызов производится вызовом прерывания 0x80 . Такой способ вызова (с передачей параметров через регистры) называется fastcall . В других системах (например, *BSD ) могут применяться другие способы вызова.
Следует отметить, что не следует использовать системные вызовы везде, где только можно, без особой необходимости. В разных версиях ядра порядок аргументов у некоторых системных вызовов отличается, и это приводит к ошибкам, которые довольно трудно найти. Поэтому стоит использовать функции стандартной библиотеки Си, ведь их сигнатуры не изменяются, что обеспечивает переносимость кода на Си. Почему бы нам не воспользоваться этим и не переносимости наших ассемблерных программ? Только если вы пишете маленький участок самого нагруженного кода и для вас недопустимы накладные расходы, вносимые вызовом стандартной библиотеки Си, — только тогда стоит использовать системные вызовы напрямую.
В качестве примера можете посмотреть код программы Hello world.
Структуры
Объявляя структуры в Си, вы не задумывались о том, как располагаются в памяти её элементы. В ассемблере понятия нет, зато есть , его адрес и смещение в этом блоке. Объясню на примере:
| 0x23 | 0x72 | 0x45 | 0x17 |
Пусть этот блок памяти размером 4 байта расположен по адресу 0x00010000 . Это значит, что адрес байта 0x23 равен 0x00010000 . Соответственно, адрес байта 0x72 равен 0x00010001 . Говорят, что байт 0x72 расположен по смещению 1 от начала блока памяти. Тогда байт 0x45 расположен по смещению 2, а байт 0x17 — по смещению 3. Таким образом, адрес элемента = базовый адрес + смещение.
Приблизительно так в ассемблере организована работа со структурами: к базовому адресу структуры прибавляется смещение, по которому находится нужный элемент. Теперь вопрос: как определить смещение? В Си компилятор руководствуется следующими правилами:
- Вся структура должна быть выровнена так, как выровнен её элемент с наибольшим выравниванием.
- Каждый элемент находится по наименьшему следующему адресу с подходящим выравниванием. Если необходимо, для этого в структуру включается нужное число байт-заполнителей.
- Размер структуры должен быть кратен её выравниванию. Если необходимо, для этого в конец структуры включается нужное число байт-заполнителей.
Примеры (внизу указано смещение элементов в байтах; заполнители обозначены XX ):
Обратите внимание на два последних примера: элементы структур одни и те же, только расположены в разном порядке. Но размер структур получился разный!
Программа: вывод размера файла
Напишем программу, которая выводит размер файла. Для этого потребуется вызвать функцию stat(2) и прочитать данные из структуры, которую она заполнит. man 2 stat :
Так, теперь осталось только вычислить смещение поля st_size : Но что это за типы — dev_t , ino_t ? Какого они размера? Следует заглянуть в заголовочный файл и узнать, что обозначено при помощи typedef . Я сделал так:
Далее, ищу в выводе препроцессора определение dev_t , нахожу:
Значит, sizeof(dev_t) = 8.
Мы бы могли и дальше продолжать искать, но в реальности всё немного по-другому. Если вы посмотрите на определение struct stat ( cpp /usr/include/sys/stat.h | less ), вы увидите поля с именами __pad1 , __pad2 , __unused4 и другие (зависит от системы). Эти поля не используются, они нужны для совместимости, и поэтому в man они не описаны. Так что самый верный способ не ошибиться — это просто попросить компилятор Си посчитать это смещение для нас (вычитаем из адреса поля адрес структуры, получаем смещение):
На моей системе программа напечатала sizeof = 88, offset = 44 . На вашей системе это значение может отличаться по описанным причинам. Теперь у нас есть все нужные данные об этой структуре, пишем программу:
Обратите внимание на обработку ошибок: если передано не 2 аргумента — выводим описание использования программы и выходим, если stat(2) вернул ошибку — выводим сообщение об ошибке и выходим.
Наверное, могут возникнуть некоторые сложности с пониманием, как расположены argc и argv в стеке. Допустим, вы запустили программу как
Тогда стек будет выглядеть приблизительно так:
Таким образом, в стек помещается два параметра: argc и указатель на первый элемент массива argv[] . Где-то в памяти расположен блок из трёх указателей: указатель на строку «./program» , указатель на строку «test-file» и указатель NULL . Нам в стеке передали адрес этого блока памяти.
Программа: печать файла наоборот
Напишем программу, которая читает со стандартного ввода всё до конца файла, а потом выводит введённые строки в обратном порядке. Для этого мы во время чтения будем помещать строки в связный список, а потом пройдем этот список в обратном порядке и напечатаем строки.