Решаем проблемы с поломанной кодировкой: accept-charset
Столкнулся с такой проблемой: многие программисты либо не знают о существовании accept-charset, либо игнорируют данный атрибут. Прийдя в свою текущую компанию я занялся разработкой REST API сервиса, но переодически на меня сваливались баги «XML response is broken for . ». Пришлось копнуть поглубже в GUI и обнаружилось отсутствие излюбленного тага. Зачем нам еще один атрибут, спросите вы?
Что такое accept-charset лучше меня уже давно описали в W3C по этой ссылке (http://www.w3.org/TR/html401/interact/forms.html#adef-accept-charset)
Давайте теперь представим ситуацию:
— у вас есть сайт
— вы указали в meta кодировку utf-8
— вы настроили серверную часть на работу с utf-8 (базу, бекенд, прочее)
Вы тестируете: заходите на сайт, отправляете с формы — все отлично. Однако проблема в том, что многие забывают:
1. в большинстве случает в браузере стоит автоопределение кодировки и ваш сайт корректно постит данные на серверную часть
2. есть люди, которые выставляют себе кодировку вручную
3. есть любители поиграться с вашим сайтом
4. прочее: боты, софт для тестирования и тд
Что же произойдет в таком случае при отсутствии сабжевого атрибута в таге FORM:
1. откройте ваш сайт
2. смените в браузере кодировку, пусть это будет ISO-8859-1
3. попробуйте ввести данные на русском или, например: немецком, с использованием умлаутов; хотите пойти дальше — попробуйте спец. символы
4. запостите вашу форму
5. откройте вашу запись в базе данных и посмотрите в какой кодировке попали туда ваши символы и как они были обработаны серверной частью
Ответ: к вам приедет текст в кодировке ISO-8859-1 потому что браузер следует стандартам и определенной последовательности в определении кодировки, а это значит, что если жестко указано ISO-8859-1, то браузер подчинится и использует ISO-8859-1 для отправки данных из формы
Как с этим бороться?
Посмотрите в заголовок топика: да, именно accept-charset=«utf-8» в таге FORM спасет вас от этой проблемной ситуации. Данный атрибут даст браузеру необходимые «знания» о том, что данные из формы следует отправлять только в кодировке utf-8 и никакой другой
Вывод: все гениальное — просто, а владеет миром в наше время информация.
Accept and Accept-Charset — Which is superior?
In HTTP you can specify in a request that your client can accept specific content in responses using the accept header, with values such as application/xml . The content type specification allows you to include parameters in the content type, such as charset=utf-8 , indicating that you can accept content with a specified character set.
There is also the accept-charset header, which specifies the character encodings which are accepted by the client.
If both headers are specified and the accept header contains content types with the charset parameter, which should be considered the superior header by the server?
I’ve sent a few example requests to various servers using Fiddler to test how they respond:
Examples
StackOverflow
Microsoft
There doesn’t seem to be any consensus around what the expected behaviour is. I am trying to look surprised.
5 Answers 5
Altough you can set media type in Accept header, the charset parameter definition for that media type is not defined anywhere in RFC 2616 (but it is not forbidden, though).
Therefore if you are going to implement a HTTP 1.1 compliant server, you shall first look for Accept-charset header, and then search for your own parameters at Accept header.
Read RFC 2616 Section 14.1 and 14.2. The Accept header does not allow you to specify a charset . You have to use the Accept-Charset header instead.
The Accept-Charset header allows a user-agent to specify the charsets it supports.
If the Accept-Charset header did not exist, a user-agent would have to specify each charset parameter for each text/* media type it accepted, e.g.
Accept: text/html;charset=US-ASCII, text/html;charset=UTF-8, text/plain;charset=US-ASCII, text/plain;charset=UTF-8

Each media-range might be followed by zero or more applicable media type parameters (e.g., charset)
So a charset parameter for each content-type is allowed. In theory a client could accept, for example, text/html only in UTF-8 and text/plain only in US-ASCII .
But it would usually make more sense to state possible charsets in the Accept-Charset header as that applies to all types mentioned in the Accept header.
If those headers’ charsets don’t overlap, the server could send status 406 Not Acceptable .
However, I wouldn’t expect fancy cross-matching from a server for various reasons. It would make the server code more complicated (and therefore more error-prone) while in practice a client would rarely send such requests. Also nowadays I would expect everything server-side is using UTF-8 and sent as-is so there’s nothing to negotiate.
Кодировки UTF-8 и Windows 1251 — просто о сложном

Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
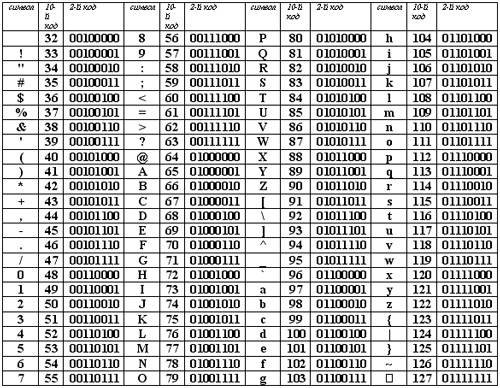
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
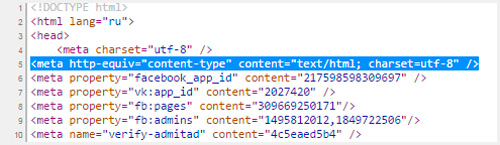
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
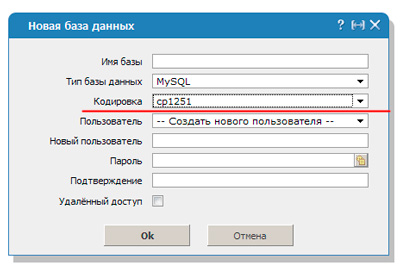
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251»
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.